Enterprise
The Rise of "o1" Models
Dec 19, 2024
5 min read

Large Langauge Models like Llama 3.2 and GPT-4o have become synonymous with Generative AI, but a new class of models is on the horizon and quickly driving adoption and innovation. Simply being referred to as “o1” like models, a better name would be Large Reasoning Models. These models are designed to generate text and reason systematically and explain their thought processes, making them uniquely suited for tasks demanding transparency and precision.
From solving complex mathematical problems to rather ugly-looking thermodynamic equations, these models promise to thrive in scenarios where logic and structure are essential for problem-solving. This blog shall explore how “o1” models emerged, their role in various domains, how to choose among the competing models, and how to use them for basic conversations!
Large Langauge Models vs. Large Reasoning Models
The era of modern AI is dominated by LLMs, celebrated for their generative capabilities that are generalized on an enormous scale. However, as demand for interpretability, accuracy, and domain-specific expertise grows, a new paradigm shift emerges in the form of Large Reasoning Models.
LLMs like GPT-4 and Claude are generalists, excelling in generating fluent and contextually relevant outputs. In contrast, reasoning models, including GPT-o1 and its alternatives, prioritize logical consistency and structured reasoning over sheer language generation capabilities. These models aim to answer “how” and “why,” offering solutions and the reasoning behind them.

Comparing "o1" Models
GPT o1: Setting the Baseline
Key Features of GPT-o1:
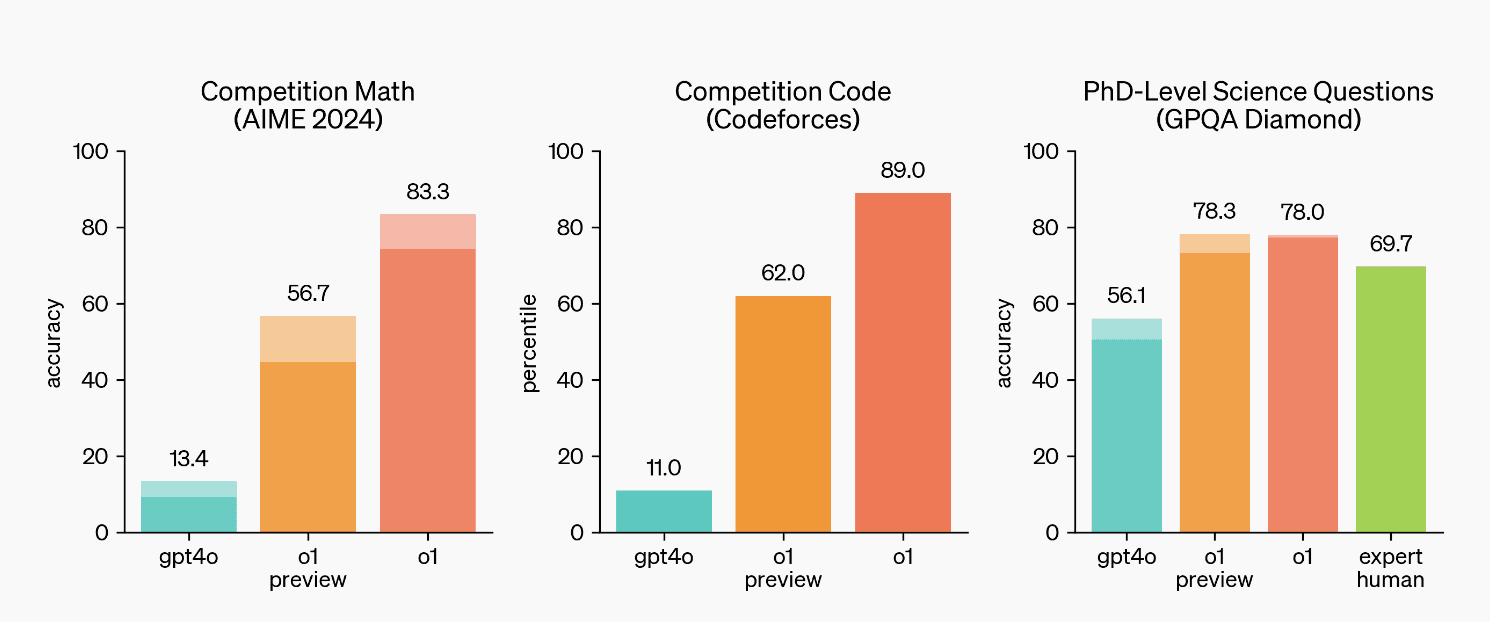
Strong emphasis on structured reasoning, breaking problems into manageable steps (Chain of Thought reasoning).
High performance in complex domains like mathematics, coding, and scientific inquiries.
The architecture prioritizes clarity and transparency in reasoning, which builds user trust in high-stakes applications.
Limitations:
Dependency on proprietary infrastructure.
Limited customizability and deployment restrictions (e.g., no local hosting or offline models).
High costs, which restrict usage for smaller organizations or individual developers.
GPT-o1's structured reasoning capabilities became a benchmark for reasoning models, inspiring successors to refine or democratize these innovations.
Qwen QwQ 32B
Builds on GPT-o1 by...
Expanding Multi-Turn Reasoning: Qwen QWQ-32B excels in iterative problem-solving across complex multi-step scenarios, especially in domains like financial analysis and logical puzzles. It optimizes memory retention during multi-turn conversations, reducing redundancy and increasing consistency.
Take a look at how the model is able to switch to Chinese for better reasoning:

Improved Mathematical Precision: Achieving higher scores on benchmarks like MATH-500 (90.6%) highlights advancements in numeric reasoning, one of GPT-o1's key strengths.
Efficiency in Contextual Understanding: Qwen QWQ introduces specific fine-tuning for nuanced contextual reasoning, which allows it to provide more accurate interpretations of ambiguous queries.
Domain-Specific Customization: Incorporates advanced fine-tuning strategies to perform exceptionally well in niche domains like quantitative analysis.

Innovations Beyond GPT-o1:
Enhanced language modeling strategies to reduce hallucinations.
Direct support for recursive reasoning, enabling models to backtrack and refine their solutions, which GPT-o1 struggled with.
Limitations: Struggles with language mixing and has ongoing safety concerns in its open-source version.
DeepSeekR1
Builds on GPT-o1 by...
Focus on Transparent Reasoning: DeepSeek R1 emphasizes step-by-step transparency in reasoning, making the logic behind its outputs explicit and verifiable. This counters GPT-o1's occasional "black-box reasoning," where the reasoning steps weren’t obvious.
Optimized for Decision-Making Tasks: Particularly tuned for solving competitive-level reasoning problems, such as AIME, which matches GPT-o1's performance while offering more straightforward explanations.
Reinforcement Learning Adjustments: Introduces user feedback loops to align reasoning more effectively with real-world contexts.
Innovations Beyond GPT-o1:
More vigorous user-interactive workflow implementation allows users to provide feedback mid-task to guide reasoning paths.
Optimized for data-constrained environments, showcasing reliable performance with smaller datasets and lower resource requirements.
Limitations: Still under development, with restricted preview access and limitations in reasoning depth for highly complex queries.
Getting Started with “o1” Type Models on Studio
Starting inference with these models takes less than a minute; here is how to use Tune Studio to talk with them for reasoning tasks.
Head to Models on Tune Studio
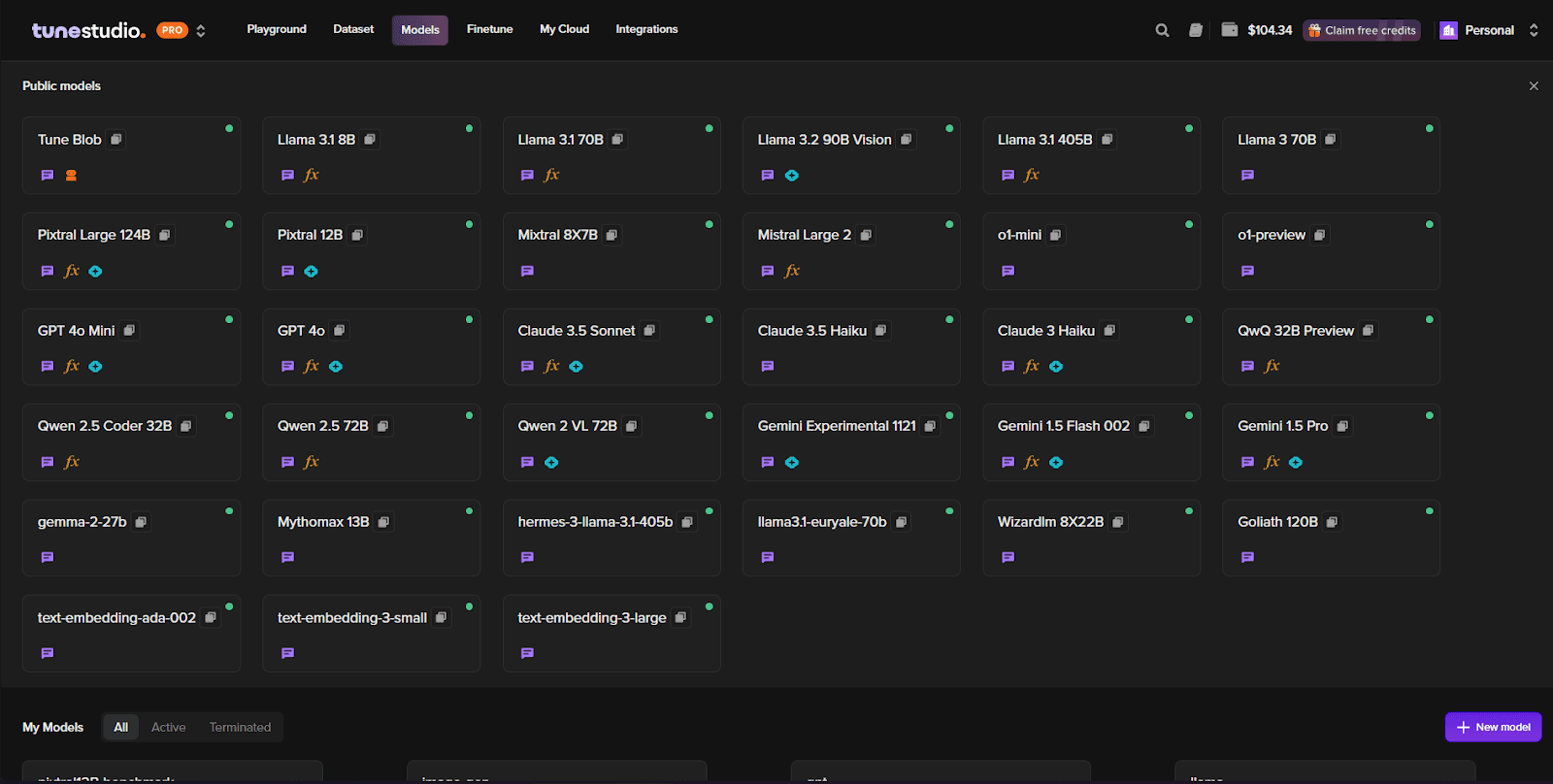
Open in Playground to Start Interacting with it:
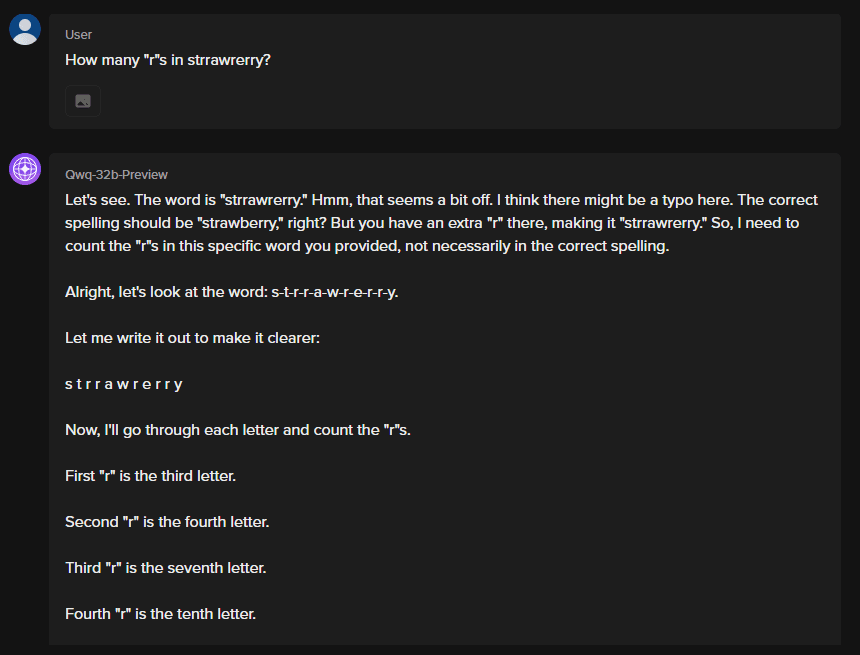
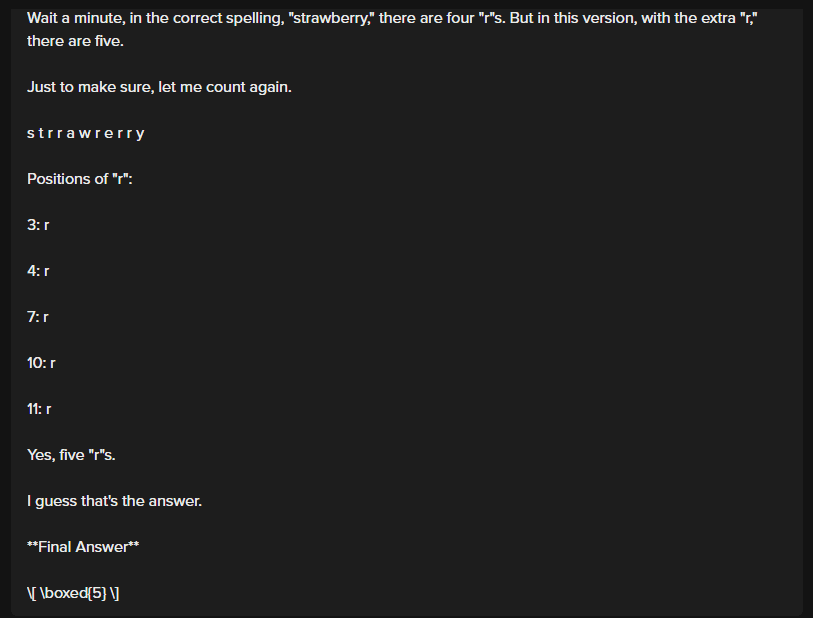
Yes, that’s how easy it is. Focusing a bit on the outputs generated by QwQ in this case, we can see that the model is somehow conversing with its thoughts, which raises questions and discussions regarding using Chain of Thought paired with a strong open-source model.
However, one standard limitation among all these models is the number of tokens required to arrive at an answer. Let us try the above example with Qwen 2.5 72B (Note: the above screenshot is truncated and includes four more lines of going through each character in the word)
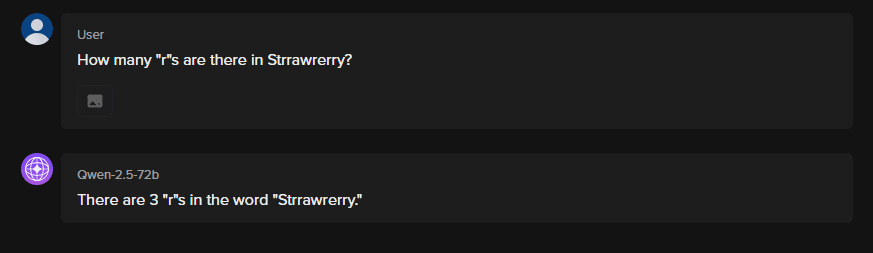
Conclusion
As AI evolves, the debate between generation and reasoning intensifies. Large Language Models (LLMs) have dominated the early stages of AI adoption, showcasing their ability to create and interpret language fluently. However, the rise of o1-style models and Large Reasoning Models (LRMs) signals a new era where accuracy, explainability, and logical consistency take center stage.
Models like GPT-o1, Qwen QWQ, and DeepSeek R1 demonstrate that reasoning-first AI is a technological advancement and a necessity for critical applications. These models are helping bridge the gap between human-like understanding and machine-like precision, addressing limitations in ambiguity and accountability that traditional LLMs often encounter.
For developers and organizations, the choice between LLMs and LRMs is not binary but contextual. Whether you're solving complex scientific problems, automating workflows, or building conversational agents, understanding the strengths of each model type will be crucial. With frameworks and open-source advancements democratizing access to o1-style reasoning, the barrier to entry is lower than ever, empowering innovators across industries.
Large Langauge Models like Llama 3.2 and GPT-4o have become synonymous with Generative AI, but a new class of models is on the horizon and quickly driving adoption and innovation. Simply being referred to as “o1” like models, a better name would be Large Reasoning Models. These models are designed to generate text and reason systematically and explain their thought processes, making them uniquely suited for tasks demanding transparency and precision.
From solving complex mathematical problems to rather ugly-looking thermodynamic equations, these models promise to thrive in scenarios where logic and structure are essential for problem-solving. This blog shall explore how “o1” models emerged, their role in various domains, how to choose among the competing models, and how to use them for basic conversations!
Large Langauge Models vs. Large Reasoning Models
The era of modern AI is dominated by LLMs, celebrated for their generative capabilities that are generalized on an enormous scale. However, as demand for interpretability, accuracy, and domain-specific expertise grows, a new paradigm shift emerges in the form of Large Reasoning Models.
LLMs like GPT-4 and Claude are generalists, excelling in generating fluent and contextually relevant outputs. In contrast, reasoning models, including GPT-o1 and its alternatives, prioritize logical consistency and structured reasoning over sheer language generation capabilities. These models aim to answer “how” and “why,” offering solutions and the reasoning behind them.
Comparing "o1" Models
GPT o1: Setting the Baseline
Key Features of GPT-o1:
Strong emphasis on structured reasoning, breaking problems into manageable steps (Chain of Thought reasoning).
High performance in complex domains like mathematics, coding, and scientific inquiries.
The architecture prioritizes clarity and transparency in reasoning, which builds user trust in high-stakes applications.
Limitations:
Dependency on proprietary infrastructure.
Limited customizability and deployment restrictions (e.g., no local hosting or offline models).
High costs, which restrict usage for smaller organizations or individual developers.
GPT-o1's structured reasoning capabilities became a benchmark for reasoning models, inspiring successors to refine or democratize these innovations.
Qwen QwQ 32B
Builds on GPT-o1 by...
Expanding Multi-Turn Reasoning: Qwen QWQ-32B excels in iterative problem-solving across complex multi-step scenarios, especially in domains like financial analysis and logical puzzles. It optimizes memory retention during multi-turn conversations, reducing redundancy and increasing consistency.
Take a look at how the model is able to switch to Chinese for better reasoning:
Improved Mathematical Precision: Achieving higher scores on benchmarks like MATH-500 (90.6%) highlights advancements in numeric reasoning, one of GPT-o1's key strengths.
Efficiency in Contextual Understanding: Qwen QWQ introduces specific fine-tuning for nuanced contextual reasoning, which allows it to provide more accurate interpretations of ambiguous queries.
Domain-Specific Customization: Incorporates advanced fine-tuning strategies to perform exceptionally well in niche domains like quantitative analysis.
Innovations Beyond GPT-o1:
Enhanced language modeling strategies to reduce hallucinations.
Direct support for recursive reasoning, enabling models to backtrack and refine their solutions, which GPT-o1 struggled with.
Limitations: Struggles with language mixing and has ongoing safety concerns in its open-source version.
DeepSeekR1
Builds on GPT-o1 by...
Focus on Transparent Reasoning: DeepSeek R1 emphasizes step-by-step transparency in reasoning, making the logic behind its outputs explicit and verifiable. This counters GPT-o1's occasional "black-box reasoning," where the reasoning steps weren’t obvious.
Optimized for Decision-Making Tasks: Particularly tuned for solving competitive-level reasoning problems, such as AIME, which matches GPT-o1's performance while offering more straightforward explanations.
Reinforcement Learning Adjustments: Introduces user feedback loops to align reasoning more effectively with real-world contexts.
Innovations Beyond GPT-o1:
More vigorous user-interactive workflow implementation allows users to provide feedback mid-task to guide reasoning paths.
Optimized for data-constrained environments, showcasing reliable performance with smaller datasets and lower resource requirements.
Limitations: Still under development, with restricted preview access and limitations in reasoning depth for highly complex queries.
Getting Started with “o1” Type Models on Studio
Starting inference with these models takes less than a minute; here is how to use Tune Studio to talk with them for reasoning tasks.
Head to Models on Tune Studio
Open in Playground to Start Interacting with it:
Yes, that’s how easy it is. Focusing a bit on the outputs generated by QwQ in this case, we can see that the model is somehow conversing with its thoughts, which raises questions and discussions regarding using Chain of Thought paired with a strong open-source model.
However, one standard limitation among all these models is the number of tokens required to arrive at an answer. Let us try the above example with Qwen 2.5 72B (Note: the above screenshot is truncated and includes four more lines of going through each character in the word)
Conclusion
As AI evolves, the debate between generation and reasoning intensifies. Large Language Models (LLMs) have dominated the early stages of AI adoption, showcasing their ability to create and interpret language fluently. However, the rise of o1-style models and Large Reasoning Models (LRMs) signals a new era where accuracy, explainability, and logical consistency take center stage.
Models like GPT-o1, Qwen QWQ, and DeepSeek R1 demonstrate that reasoning-first AI is a technological advancement and a necessity for critical applications. These models are helping bridge the gap between human-like understanding and machine-like precision, addressing limitations in ambiguity and accountability that traditional LLMs often encounter.
For developers and organizations, the choice between LLMs and LRMs is not binary but contextual. Whether you're solving complex scientific problems, automating workflows, or building conversational agents, understanding the strengths of each model type will be crucial. With frameworks and open-source advancements democratizing access to o1-style reasoning, the barrier to entry is lower than ever, empowering innovators across industries.
Large Langauge Models like Llama 3.2 and GPT-4o have become synonymous with Generative AI, but a new class of models is on the horizon and quickly driving adoption and innovation. Simply being referred to as “o1” like models, a better name would be Large Reasoning Models. These models are designed to generate text and reason systematically and explain their thought processes, making them uniquely suited for tasks demanding transparency and precision.
From solving complex mathematical problems to rather ugly-looking thermodynamic equations, these models promise to thrive in scenarios where logic and structure are essential for problem-solving. This blog shall explore how “o1” models emerged, their role in various domains, how to choose among the competing models, and how to use them for basic conversations!
Large Langauge Models vs. Large Reasoning Models
The era of modern AI is dominated by LLMs, celebrated for their generative capabilities that are generalized on an enormous scale. However, as demand for interpretability, accuracy, and domain-specific expertise grows, a new paradigm shift emerges in the form of Large Reasoning Models.
LLMs like GPT-4 and Claude are generalists, excelling in generating fluent and contextually relevant outputs. In contrast, reasoning models, including GPT-o1 and its alternatives, prioritize logical consistency and structured reasoning over sheer language generation capabilities. These models aim to answer “how” and “why,” offering solutions and the reasoning behind them.
Comparing "o1" Models
GPT o1: Setting the Baseline
Key Features of GPT-o1:
Strong emphasis on structured reasoning, breaking problems into manageable steps (Chain of Thought reasoning).
High performance in complex domains like mathematics, coding, and scientific inquiries.
The architecture prioritizes clarity and transparency in reasoning, which builds user trust in high-stakes applications.
Limitations:
Dependency on proprietary infrastructure.
Limited customizability and deployment restrictions (e.g., no local hosting or offline models).
High costs, which restrict usage for smaller organizations or individual developers.
GPT-o1's structured reasoning capabilities became a benchmark for reasoning models, inspiring successors to refine or democratize these innovations.
Qwen QwQ 32B
Builds on GPT-o1 by...
Expanding Multi-Turn Reasoning: Qwen QWQ-32B excels in iterative problem-solving across complex multi-step scenarios, especially in domains like financial analysis and logical puzzles. It optimizes memory retention during multi-turn conversations, reducing redundancy and increasing consistency.
Take a look at how the model is able to switch to Chinese for better reasoning:
Improved Mathematical Precision: Achieving higher scores on benchmarks like MATH-500 (90.6%) highlights advancements in numeric reasoning, one of GPT-o1's key strengths.
Efficiency in Contextual Understanding: Qwen QWQ introduces specific fine-tuning for nuanced contextual reasoning, which allows it to provide more accurate interpretations of ambiguous queries.
Domain-Specific Customization: Incorporates advanced fine-tuning strategies to perform exceptionally well in niche domains like quantitative analysis.
Innovations Beyond GPT-o1:
Enhanced language modeling strategies to reduce hallucinations.
Direct support for recursive reasoning, enabling models to backtrack and refine their solutions, which GPT-o1 struggled with.
Limitations: Struggles with language mixing and has ongoing safety concerns in its open-source version.
DeepSeekR1
Builds on GPT-o1 by...
Focus on Transparent Reasoning: DeepSeek R1 emphasizes step-by-step transparency in reasoning, making the logic behind its outputs explicit and verifiable. This counters GPT-o1's occasional "black-box reasoning," where the reasoning steps weren’t obvious.
Optimized for Decision-Making Tasks: Particularly tuned for solving competitive-level reasoning problems, such as AIME, which matches GPT-o1's performance while offering more straightforward explanations.
Reinforcement Learning Adjustments: Introduces user feedback loops to align reasoning more effectively with real-world contexts.
Innovations Beyond GPT-o1:
More vigorous user-interactive workflow implementation allows users to provide feedback mid-task to guide reasoning paths.
Optimized for data-constrained environments, showcasing reliable performance with smaller datasets and lower resource requirements.
Limitations: Still under development, with restricted preview access and limitations in reasoning depth for highly complex queries.
Getting Started with “o1” Type Models on Studio
Starting inference with these models takes less than a minute; here is how to use Tune Studio to talk with them for reasoning tasks.
Head to Models on Tune Studio
Open in Playground to Start Interacting with it:
Yes, that’s how easy it is. Focusing a bit on the outputs generated by QwQ in this case, we can see that the model is somehow conversing with its thoughts, which raises questions and discussions regarding using Chain of Thought paired with a strong open-source model.
However, one standard limitation among all these models is the number of tokens required to arrive at an answer. Let us try the above example with Qwen 2.5 72B (Note: the above screenshot is truncated and includes four more lines of going through each character in the word)
Conclusion
As AI evolves, the debate between generation and reasoning intensifies. Large Language Models (LLMs) have dominated the early stages of AI adoption, showcasing their ability to create and interpret language fluently. However, the rise of o1-style models and Large Reasoning Models (LRMs) signals a new era where accuracy, explainability, and logical consistency take center stage.
Models like GPT-o1, Qwen QWQ, and DeepSeek R1 demonstrate that reasoning-first AI is a technological advancement and a necessity for critical applications. These models are helping bridge the gap between human-like understanding and machine-like precision, addressing limitations in ambiguity and accountability that traditional LLMs often encounter.
For developers and organizations, the choice between LLMs and LRMs is not binary but contextual. Whether you're solving complex scientific problems, automating workflows, or building conversational agents, understanding the strengths of each model type will be crucial. With frameworks and open-source advancements democratizing access to o1-style reasoning, the barrier to entry is lower than ever, empowering innovators across industries.
Written by

Aryan Kargwal
Data Evangelist
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.