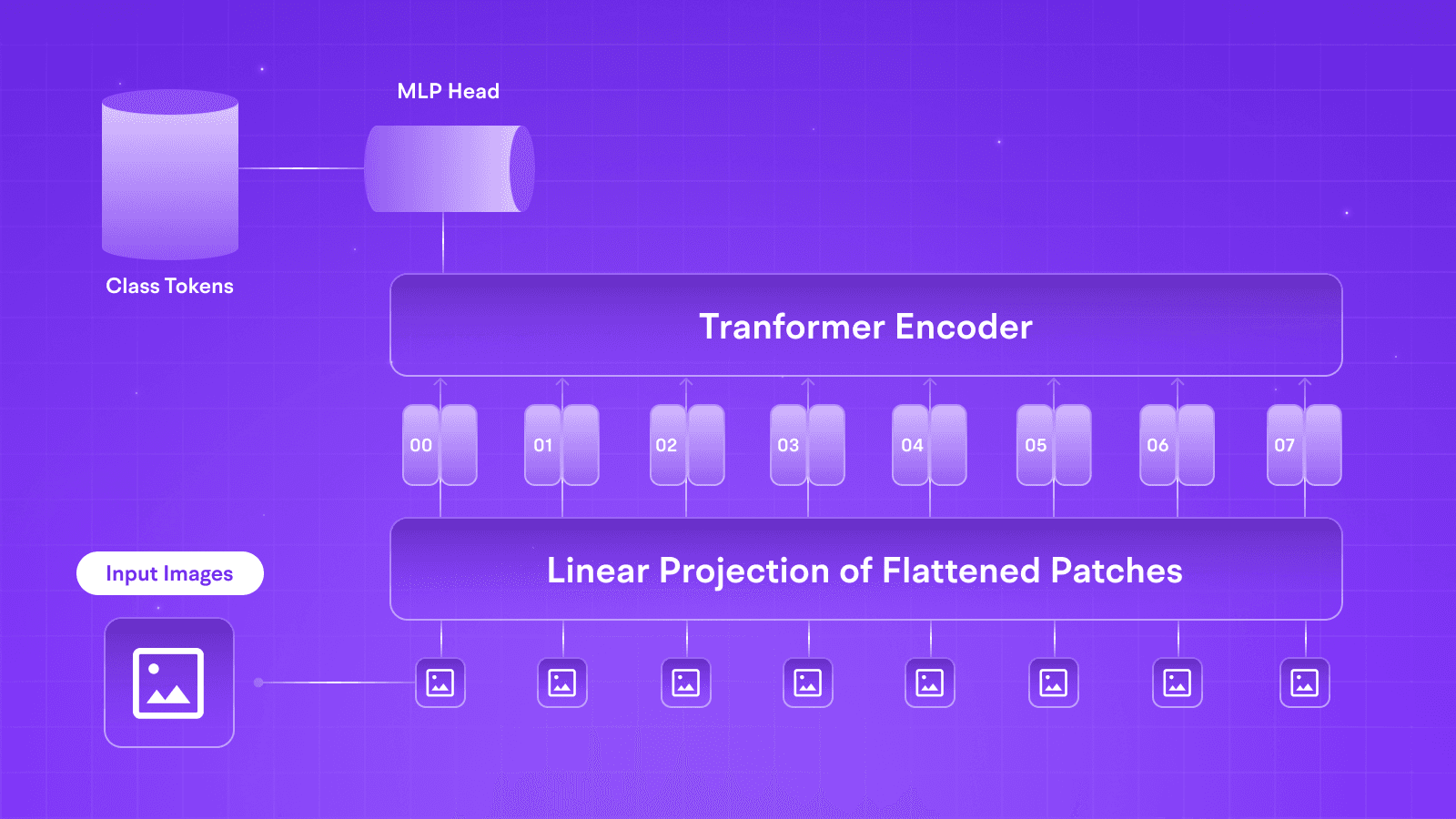
LLMs
Comparing vLLM and TGI for hosting LLMs
Mar 25, 2024
3 min read

Welcome to our latest blog post, where we put vLLM and TGI to the test in a battle of the large language models! In our previous blog post, we evaluated the performance of the Goliath 120B model for one of our customers. We wanted to determine how to optimize its use for approximately 1,000 DAUs (Daily Active Users), and we found that running it in FP16 or EETQ format resulted in the fastest performance.
In this post, we will focus on the Mixtral 8x7B and Goliath 120B and compare their latencies w.r.t. rpm. We will compare TGI and vLLM to see which is better. And let us tell you, the results were nothing short of thrilling!
Benchmark Results
Here are the results of our benchmark tests:
vLLM is ~15% faster in latencies compared to TGI
We compared the latencies of vLLM and TGI for both models with 30 req/min, running on 4xA100. Here are the results:
Mixtral 8x7B


Goliath 120B


Just look at those charts! vLLM has a significant advantage in latency over TGI.
vLLM is more stable at higher load
But that's not all. We also tested the stability of vLLM and TGI under higher loads for both models.
NOTE: Because of constraints, we could only benchmark TGI on H100s and vLLM on A100. But as you will see, vLLM still competes with TGI when running on less powerful hardware, thus reducing cost.
We are redoing the TGI benchmarks on A100 and have an update soon!
Goliath 120 req/min
TGI 8xH100

vLLM 4xA100

Mixtral 180 req/min
TGI 4xH100

vLLM 4xA100

Mixtral 240 req/min
vLLM 4xA100

It's clear from these charts that vLLM is more stable at higher loads compared to TGI.
The difference is significant, especially for Mixtral/other 7B models where TGI cannot handle 180 & 240 rpm at a constant latency but vLLM can.

Conclusion
After conducting benchmark tests for the Mixtral 8x7B and Goliath 120B models, we found that vLLM has a significant advantage in latency over TGI, with vLLM being ~15% faster. We also tested the stability of both models under higher loads, and vLLM proved to be more stable, even when running on less powerful hardware.
These results suggest that vLLM may be the superior choice for large language model benchmarking, especially for models like Mixtral which has a lower # of parameters. The fact that vLLM can handle higher loads and maintain stable latencies is particularly noteworthy, as it can help reduce costs and improve the user experience.
Check out our previous blog post for more information on our testing process and results!
Welcome to our latest blog post, where we put vLLM and TGI to the test in a battle of the large language models! In our previous blog post, we evaluated the performance of the Goliath 120B model for one of our customers. We wanted to determine how to optimize its use for approximately 1,000 DAUs (Daily Active Users), and we found that running it in FP16 or EETQ format resulted in the fastest performance.
In this post, we will focus on the Mixtral 8x7B and Goliath 120B and compare their latencies w.r.t. rpm. We will compare TGI and vLLM to see which is better. And let us tell you, the results were nothing short of thrilling!
Benchmark Results
Here are the results of our benchmark tests:
vLLM is ~15% faster in latencies compared to TGI
We compared the latencies of vLLM and TGI for both models with 30 req/min, running on 4xA100. Here are the results:
Mixtral 8x7B
Goliath 120B
Just look at those charts! vLLM has a significant advantage in latency over TGI.
vLLM is more stable at higher load
But that's not all. We also tested the stability of vLLM and TGI under higher loads for both models.
NOTE: Because of constraints, we could only benchmark TGI on H100s and vLLM on A100. But as you will see, vLLM still competes with TGI when running on less powerful hardware, thus reducing cost.
We are redoing the TGI benchmarks on A100 and have an update soon!
Goliath 120 req/min
TGI 8xH100
vLLM 4xA100
Mixtral 180 req/min
TGI 4xH100
vLLM 4xA100
Mixtral 240 req/min
vLLM 4xA100
It's clear from these charts that vLLM is more stable at higher loads compared to TGI.
The difference is significant, especially for Mixtral/other 7B models where TGI cannot handle 180 & 240 rpm at a constant latency but vLLM can.
Conclusion
After conducting benchmark tests for the Mixtral 8x7B and Goliath 120B models, we found that vLLM has a significant advantage in latency over TGI, with vLLM being ~15% faster. We also tested the stability of both models under higher loads, and vLLM proved to be more stable, even when running on less powerful hardware.
These results suggest that vLLM may be the superior choice for large language model benchmarking, especially for models like Mixtral which has a lower # of parameters. The fact that vLLM can handle higher loads and maintain stable latencies is particularly noteworthy, as it can help reduce costs and improve the user experience.
Check out our previous blog post for more information on our testing process and results!
Welcome to our latest blog post, where we put vLLM and TGI to the test in a battle of the large language models! In our previous blog post, we evaluated the performance of the Goliath 120B model for one of our customers. We wanted to determine how to optimize its use for approximately 1,000 DAUs (Daily Active Users), and we found that running it in FP16 or EETQ format resulted in the fastest performance.
In this post, we will focus on the Mixtral 8x7B and Goliath 120B and compare their latencies w.r.t. rpm. We will compare TGI and vLLM to see which is better. And let us tell you, the results were nothing short of thrilling!
Benchmark Results
Here are the results of our benchmark tests:
vLLM is ~15% faster in latencies compared to TGI
We compared the latencies of vLLM and TGI for both models with 30 req/min, running on 4xA100. Here are the results:
Mixtral 8x7B
Goliath 120B
Just look at those charts! vLLM has a significant advantage in latency over TGI.
vLLM is more stable at higher load
But that's not all. We also tested the stability of vLLM and TGI under higher loads for both models.
NOTE: Because of constraints, we could only benchmark TGI on H100s and vLLM on A100. But as you will see, vLLM still competes with TGI when running on less powerful hardware, thus reducing cost.
We are redoing the TGI benchmarks on A100 and have an update soon!
Goliath 120 req/min
TGI 8xH100
vLLM 4xA100
Mixtral 180 req/min
TGI 4xH100
vLLM 4xA100
Mixtral 240 req/min
vLLM 4xA100
It's clear from these charts that vLLM is more stable at higher loads compared to TGI.
The difference is significant, especially for Mixtral/other 7B models where TGI cannot handle 180 & 240 rpm at a constant latency but vLLM can.
Conclusion
After conducting benchmark tests for the Mixtral 8x7B and Goliath 120B models, we found that vLLM has a significant advantage in latency over TGI, with vLLM being ~15% faster. We also tested the stability of both models under higher loads, and vLLM proved to be more stable, even when running on less powerful hardware.
These results suggest that vLLM may be the superior choice for large language model benchmarking, especially for models like Mixtral which has a lower # of parameters. The fact that vLLM can handle higher loads and maintain stable latencies is particularly noteworthy, as it can help reduce costs and improve the user experience.
Check out our previous blog post for more information on our testing process and results!
Written by

Rohan Pooniwala
CTO


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.