LLMs
Tracing VLM Origins: Vision Transformer
Nov 25, 2024
4 min read
One name consistently emerges when examining the core operations and integration of transformers in computer vision: Vision Transformers (ViTs). But what exactly are these terms, and how have these modern “black box” transformers come to dominate the field of computer vision, particularly after the decline of the CNN era?
This blog will delve into the Vision Transformer paper, “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale,” which presents an innovative application of the original transformer architecture for vision tasks. As we explore additional influential papers, this series aims to demystify popular Vision-Language Models (VLMs) and provide insights into how one can innovate and refine approaches in this rapidly evolving field.
Vision Transformer
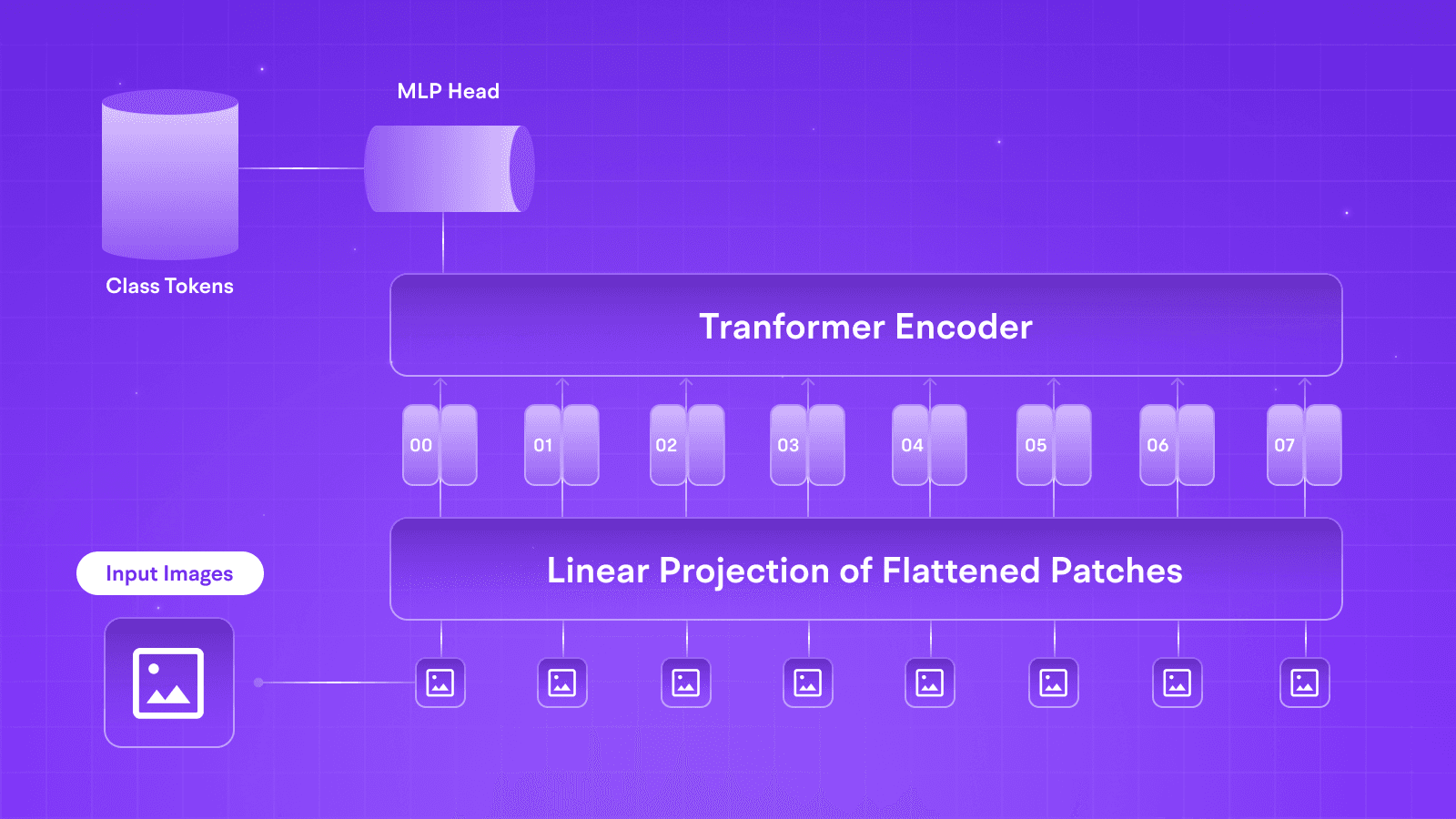
The Vision Transformer (ViT) processes images differently from traditional Convolutional Neural Networks (CNNs) by dividing the image into fixed-size patches rather than interacting with individual pixels. Each patch is then flattened into a vector, with dimensions defined by the patch size and the number of color channels. This transformation allows the ViT to handle an image more efficiently by treating the patches as individual tokens, akin to how language transformers treat words.
Since transformers don’t innately understand the spatial relationships between these patches, positional embeddings are added to each patch to encode its position within the image. This enables the model to learn and maintain the spatial relationships between patches, which is crucial for understanding the overall structure of the image.
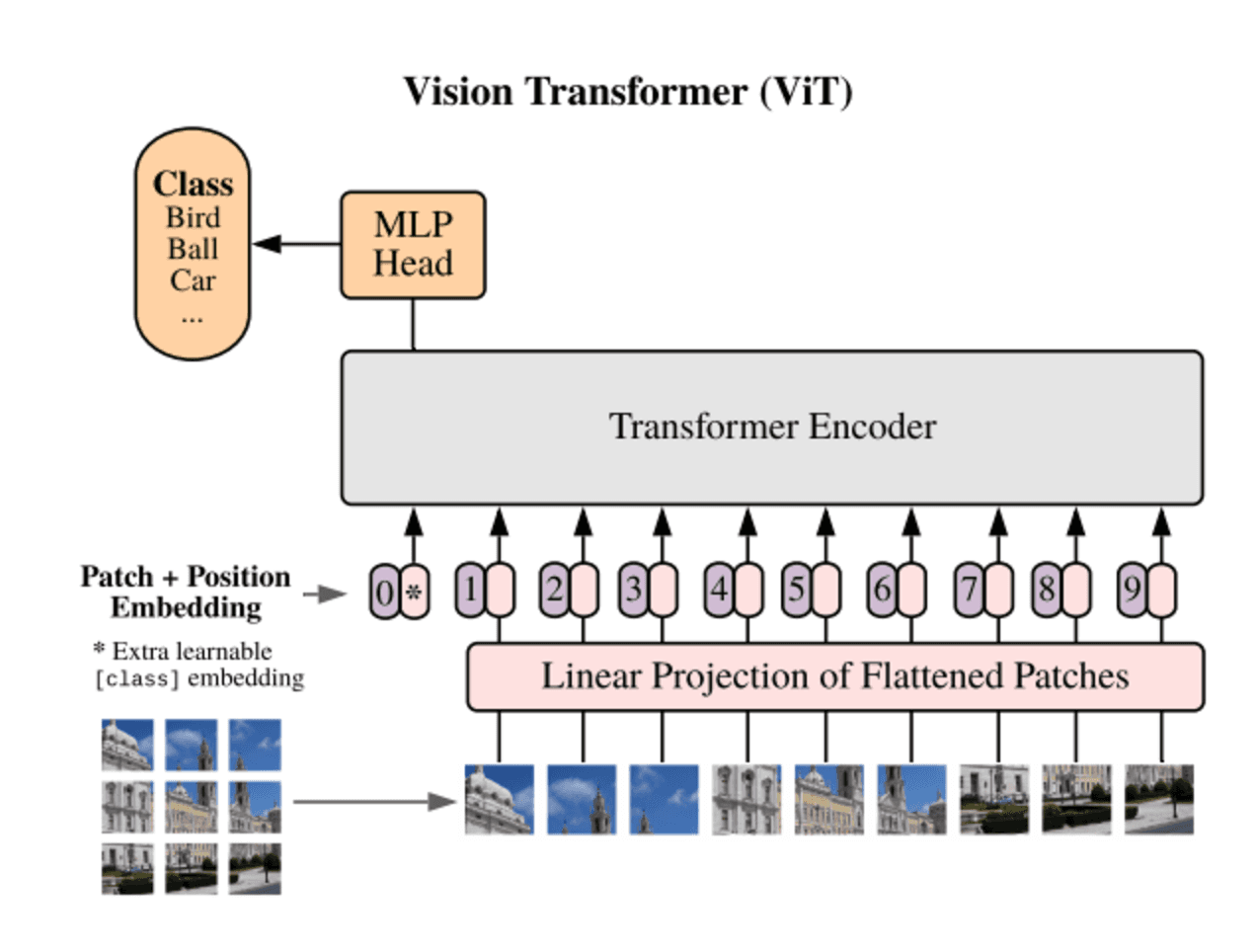
Fig 1: Vision Transformer Architecture
Once the image patches are embedded and combined with positional encodings, they are fed into the standard transformer encoder architecture. Using its Multi-Head Self-Attention mechanism, the encoder computes patch relationships and extracts global image features. ViT introduces a classification token during the encoding step, which is used to help the Multi-Layer Perceptron (MLP) with the final classification task. The MLP, consisting of two layers and activated by Gaussian Error Linear Units (GELU), adds non-linearity to the model and supports classification.
The transformer’s global attention mechanism allows ViT to process an image holistically, giving it an edge over CNNs, which rely on local convolutional filters. This global feature extraction, coupled with the model's ability to scale quickly for higher resolution images by adjusting layer numbers and patch sizes, makes ViT particularly powerful for handling large datasets like ImageNet or JFT-300M, which has outperformed many CNN architectures.
Strengths
Global Attention: ViT’s Self-Attention mechanism enables global feature extraction; unlike CNNs that rely on local convolutional filters, ViT can holistically process an image.
Data-Management: The model is exceptionally good at handling more enormous datasets, and its performance shines in benchmarks such as ImageNet or JFT-300M, which surpasses ResNet and lower CNN architectures at that point.
Scalability: The transformer architecture enables the model to adapt for higher resolution images or more detailed images by simply manipulating the layer numbers and patch sizes.
Weaknesses
Data-Hungry: ViT relies on copious amounts of data and struggles with generalization or lack thereof because of the inherent Transformer architecture. Smaller datasets lead to extreme overfitting, rendering them useless compared to CNN-based architectures like Mask RCNN or EfficientNet.
Lack of Convolutional Inductive Bias: ViT does not incorporate the hierarchical feature extraction commonly seen in CNNs, which becomes a problem with the lack of data as it doesn’t leverage local patterns like edges or textures, which are helpful in vision tasks, especially those deployed in real life.
Further Analysis
Analyzing further, referring to “Training data-efficient image transformers & distillation through attention” and their breakdown and analysis of ViT’s performance on different models compared to SOTA CNN Architectures.
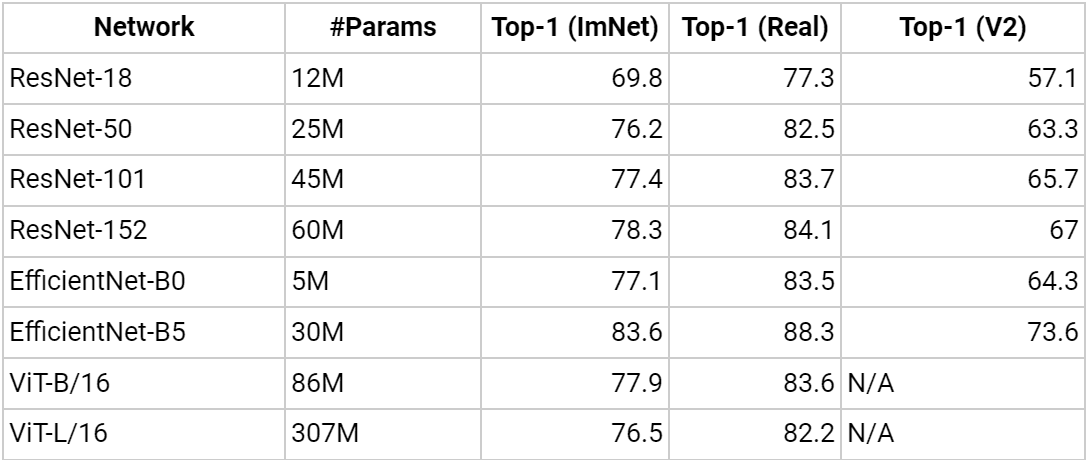
When we compare different models’ performance against ViT, we see models like ResNet, where ViT easily achieves the performance of their deepest variants. This is notable as we notice that ResNet's performance stagnates as we increase the number of layers. In contrast, for ViT, we can simply increase the number of layers for a performance boost.
However, this is where we notice a shortcoming of the Vision Transformer compared to a CNN-like Efficient Net, which is an efficient representation of ResNet architectures and easily outperforms ViT while keeping a minimal number of parameters.
Inspired Architectures and Key-Related Works
The success of Vision Transformer inspired numerous derivative architectures and innovative approaches to address limitations and expand the transformer model’s applicability to a broader range of visual tasks, including segmentation, detection, and self-supervised learning. Some notable advancements include:
Patch-Based Methods and Improved Patch Interaction: Several studies have refined ViT’s patch extraction and processing methods to improve performance.
Swin Transformer (2021) by Liu et al.: Introduces a hierarchical architecture with shifted windows for efficient computation. Swin adopts local self-attention within non-overlapping windows, enabling it to capture local features at lower layers and expand globally in deeper layers, making it highly effective for dense prediction tasks such as image segmentation.
Masked Autoencoders (2022) by He et al.: This approach masks portions of the input image during training, prompting the model to reconstruct the missing context. This self-supervised technique reduces the need for extensive labeled data and further improves ViT’s training efficiency.
DINO (2021) by Caron et al.: Implements self-supervised learning with a Momentum Teacher Network and multi-crop training, where a student network learns by matching predictions from the teacher network across augmentations, enhancing ViT’s robustness.
Hierarchical Feature Extraction: Models like Swin and TransUNet demonstrate that incorporating hierarchical or pyramid-based structures enables transformers to handle dense predictions more effectively.
TransUNet (2021) by Chen et al.: Combines the ViT architecture with U-Net to leverage global context modeling and U-Net’s spatial retention, making it suitable for medical image segmentation.
Pyramid Vision Transformer (2021) by Wang et al.: Integrates a pyramid structure to capture features across multiple scales, enhancing ViT’s capability for dense predictions on high-resolution images.
DeiT (2021) by Touvron et al.: Developed to make ViT effective with limited data, DeiT employs a distillation-based approach with a CNN teacher model, helping train ViT on smaller datasets.
SegFormer (2021) by Xie et al.: Uses a lightweight MLP decoder to aggregate multi-scale features across the model’s layers, improving segmentation performance while achieving efficiency gains over traditional CNN-based segmentation models.
Conclusion
The rise of Vision Transformers (ViTs) marks a revolutionary shift in computer vision, challenging the long-standing dominance of Convolutional Neural Networks (CNNs). With their unique ability to process images globally and holistically through self-attention, ViTs have demonstrated remarkable scalability and performance, particularly in handling large datasets and high-resolution photos.
Vision Transformers and their derivatives are poised to remain at the forefront of computer vision research and applications. With ongoing developments to enhance their efficiency and effectiveness, the field will continue to evolve, offering new opportunities for innovation and application.
One name consistently emerges when examining the core operations and integration of transformers in computer vision: Vision Transformers (ViTs). But what exactly are these terms, and how have these modern “black box” transformers come to dominate the field of computer vision, particularly after the decline of the CNN era?
This blog will delve into the Vision Transformer paper, “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale,” which presents an innovative application of the original transformer architecture for vision tasks. As we explore additional influential papers, this series aims to demystify popular Vision-Language Models (VLMs) and provide insights into how one can innovate and refine approaches in this rapidly evolving field.
Vision Transformer
The Vision Transformer (ViT) processes images differently from traditional Convolutional Neural Networks (CNNs) by dividing the image into fixed-size patches rather than interacting with individual pixels. Each patch is then flattened into a vector, with dimensions defined by the patch size and the number of color channels. This transformation allows the ViT to handle an image more efficiently by treating the patches as individual tokens, akin to how language transformers treat words.
Since transformers don’t innately understand the spatial relationships between these patches, positional embeddings are added to each patch to encode its position within the image. This enables the model to learn and maintain the spatial relationships between patches, which is crucial for understanding the overall structure of the image.
Fig 1: Vision Transformer Architecture
Once the image patches are embedded and combined with positional encodings, they are fed into the standard transformer encoder architecture. Using its Multi-Head Self-Attention mechanism, the encoder computes patch relationships and extracts global image features. ViT introduces a classification token during the encoding step, which is used to help the Multi-Layer Perceptron (MLP) with the final classification task. The MLP, consisting of two layers and activated by Gaussian Error Linear Units (GELU), adds non-linearity to the model and supports classification.
The transformer’s global attention mechanism allows ViT to process an image holistically, giving it an edge over CNNs, which rely on local convolutional filters. This global feature extraction, coupled with the model's ability to scale quickly for higher resolution images by adjusting layer numbers and patch sizes, makes ViT particularly powerful for handling large datasets like ImageNet or JFT-300M, which has outperformed many CNN architectures.
Strengths
Global Attention: ViT’s Self-Attention mechanism enables global feature extraction; unlike CNNs that rely on local convolutional filters, ViT can holistically process an image.
Data-Management: The model is exceptionally good at handling more enormous datasets, and its performance shines in benchmarks such as ImageNet or JFT-300M, which surpasses ResNet and lower CNN architectures at that point.
Scalability: The transformer architecture enables the model to adapt for higher resolution images or more detailed images by simply manipulating the layer numbers and patch sizes.
Weaknesses
Data-Hungry: ViT relies on copious amounts of data and struggles with generalization or lack thereof because of the inherent Transformer architecture. Smaller datasets lead to extreme overfitting, rendering them useless compared to CNN-based architectures like Mask RCNN or EfficientNet.
Lack of Convolutional Inductive Bias: ViT does not incorporate the hierarchical feature extraction commonly seen in CNNs, which becomes a problem with the lack of data as it doesn’t leverage local patterns like edges or textures, which are helpful in vision tasks, especially those deployed in real life.
Further Analysis
Analyzing further, referring to “Training data-efficient image transformers & distillation through attention” and their breakdown and analysis of ViT’s performance on different models compared to SOTA CNN Architectures.
When we compare different models’ performance against ViT, we see models like ResNet, where ViT easily achieves the performance of their deepest variants. This is notable as we notice that ResNet's performance stagnates as we increase the number of layers. In contrast, for ViT, we can simply increase the number of layers for a performance boost.
However, this is where we notice a shortcoming of the Vision Transformer compared to a CNN-like Efficient Net, which is an efficient representation of ResNet architectures and easily outperforms ViT while keeping a minimal number of parameters.
Inspired Architectures and Key-Related Works
The success of Vision Transformer inspired numerous derivative architectures and innovative approaches to address limitations and expand the transformer model’s applicability to a broader range of visual tasks, including segmentation, detection, and self-supervised learning. Some notable advancements include:
Patch-Based Methods and Improved Patch Interaction: Several studies have refined ViT’s patch extraction and processing methods to improve performance.
Swin Transformer (2021) by Liu et al.: Introduces a hierarchical architecture with shifted windows for efficient computation. Swin adopts local self-attention within non-overlapping windows, enabling it to capture local features at lower layers and expand globally in deeper layers, making it highly effective for dense prediction tasks such as image segmentation.
Masked Autoencoders (2022) by He et al.: This approach masks portions of the input image during training, prompting the model to reconstruct the missing context. This self-supervised technique reduces the need for extensive labeled data and further improves ViT’s training efficiency.
DINO (2021) by Caron et al.: Implements self-supervised learning with a Momentum Teacher Network and multi-crop training, where a student network learns by matching predictions from the teacher network across augmentations, enhancing ViT’s robustness.
Hierarchical Feature Extraction: Models like Swin and TransUNet demonstrate that incorporating hierarchical or pyramid-based structures enables transformers to handle dense predictions more effectively.
TransUNet (2021) by Chen et al.: Combines the ViT architecture with U-Net to leverage global context modeling and U-Net’s spatial retention, making it suitable for medical image segmentation.
Pyramid Vision Transformer (2021) by Wang et al.: Integrates a pyramid structure to capture features across multiple scales, enhancing ViT’s capability for dense predictions on high-resolution images.
DeiT (2021) by Touvron et al.: Developed to make ViT effective with limited data, DeiT employs a distillation-based approach with a CNN teacher model, helping train ViT on smaller datasets.
SegFormer (2021) by Xie et al.: Uses a lightweight MLP decoder to aggregate multi-scale features across the model’s layers, improving segmentation performance while achieving efficiency gains over traditional CNN-based segmentation models.
Conclusion
The rise of Vision Transformers (ViTs) marks a revolutionary shift in computer vision, challenging the long-standing dominance of Convolutional Neural Networks (CNNs). With their unique ability to process images globally and holistically through self-attention, ViTs have demonstrated remarkable scalability and performance, particularly in handling large datasets and high-resolution photos.
Vision Transformers and their derivatives are poised to remain at the forefront of computer vision research and applications. With ongoing developments to enhance their efficiency and effectiveness, the field will continue to evolve, offering new opportunities for innovation and application.
One name consistently emerges when examining the core operations and integration of transformers in computer vision: Vision Transformers (ViTs). But what exactly are these terms, and how have these modern “black box” transformers come to dominate the field of computer vision, particularly after the decline of the CNN era?
This blog will delve into the Vision Transformer paper, “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale,” which presents an innovative application of the original transformer architecture for vision tasks. As we explore additional influential papers, this series aims to demystify popular Vision-Language Models (VLMs) and provide insights into how one can innovate and refine approaches in this rapidly evolving field.
Vision Transformer
The Vision Transformer (ViT) processes images differently from traditional Convolutional Neural Networks (CNNs) by dividing the image into fixed-size patches rather than interacting with individual pixels. Each patch is then flattened into a vector, with dimensions defined by the patch size and the number of color channels. This transformation allows the ViT to handle an image more efficiently by treating the patches as individual tokens, akin to how language transformers treat words.
Since transformers don’t innately understand the spatial relationships between these patches, positional embeddings are added to each patch to encode its position within the image. This enables the model to learn and maintain the spatial relationships between patches, which is crucial for understanding the overall structure of the image.
Fig 1: Vision Transformer Architecture
Once the image patches are embedded and combined with positional encodings, they are fed into the standard transformer encoder architecture. Using its Multi-Head Self-Attention mechanism, the encoder computes patch relationships and extracts global image features. ViT introduces a classification token during the encoding step, which is used to help the Multi-Layer Perceptron (MLP) with the final classification task. The MLP, consisting of two layers and activated by Gaussian Error Linear Units (GELU), adds non-linearity to the model and supports classification.
The transformer’s global attention mechanism allows ViT to process an image holistically, giving it an edge over CNNs, which rely on local convolutional filters. This global feature extraction, coupled with the model's ability to scale quickly for higher resolution images by adjusting layer numbers and patch sizes, makes ViT particularly powerful for handling large datasets like ImageNet or JFT-300M, which has outperformed many CNN architectures.
Strengths
Global Attention: ViT’s Self-Attention mechanism enables global feature extraction; unlike CNNs that rely on local convolutional filters, ViT can holistically process an image.
Data-Management: The model is exceptionally good at handling more enormous datasets, and its performance shines in benchmarks such as ImageNet or JFT-300M, which surpasses ResNet and lower CNN architectures at that point.
Scalability: The transformer architecture enables the model to adapt for higher resolution images or more detailed images by simply manipulating the layer numbers and patch sizes.
Weaknesses
Data-Hungry: ViT relies on copious amounts of data and struggles with generalization or lack thereof because of the inherent Transformer architecture. Smaller datasets lead to extreme overfitting, rendering them useless compared to CNN-based architectures like Mask RCNN or EfficientNet.
Lack of Convolutional Inductive Bias: ViT does not incorporate the hierarchical feature extraction commonly seen in CNNs, which becomes a problem with the lack of data as it doesn’t leverage local patterns like edges or textures, which are helpful in vision tasks, especially those deployed in real life.
Further Analysis
Analyzing further, referring to “Training data-efficient image transformers & distillation through attention” and their breakdown and analysis of ViT’s performance on different models compared to SOTA CNN Architectures.
When we compare different models’ performance against ViT, we see models like ResNet, where ViT easily achieves the performance of their deepest variants. This is notable as we notice that ResNet's performance stagnates as we increase the number of layers. In contrast, for ViT, we can simply increase the number of layers for a performance boost.
However, this is where we notice a shortcoming of the Vision Transformer compared to a CNN-like Efficient Net, which is an efficient representation of ResNet architectures and easily outperforms ViT while keeping a minimal number of parameters.
Inspired Architectures and Key-Related Works
The success of Vision Transformer inspired numerous derivative architectures and innovative approaches to address limitations and expand the transformer model’s applicability to a broader range of visual tasks, including segmentation, detection, and self-supervised learning. Some notable advancements include:
Patch-Based Methods and Improved Patch Interaction: Several studies have refined ViT’s patch extraction and processing methods to improve performance.
Swin Transformer (2021) by Liu et al.: Introduces a hierarchical architecture with shifted windows for efficient computation. Swin adopts local self-attention within non-overlapping windows, enabling it to capture local features at lower layers and expand globally in deeper layers, making it highly effective for dense prediction tasks such as image segmentation.
Masked Autoencoders (2022) by He et al.: This approach masks portions of the input image during training, prompting the model to reconstruct the missing context. This self-supervised technique reduces the need for extensive labeled data and further improves ViT’s training efficiency.
DINO (2021) by Caron et al.: Implements self-supervised learning with a Momentum Teacher Network and multi-crop training, where a student network learns by matching predictions from the teacher network across augmentations, enhancing ViT’s robustness.
Hierarchical Feature Extraction: Models like Swin and TransUNet demonstrate that incorporating hierarchical or pyramid-based structures enables transformers to handle dense predictions more effectively.
TransUNet (2021) by Chen et al.: Combines the ViT architecture with U-Net to leverage global context modeling and U-Net’s spatial retention, making it suitable for medical image segmentation.
Pyramid Vision Transformer (2021) by Wang et al.: Integrates a pyramid structure to capture features across multiple scales, enhancing ViT’s capability for dense predictions on high-resolution images.
DeiT (2021) by Touvron et al.: Developed to make ViT effective with limited data, DeiT employs a distillation-based approach with a CNN teacher model, helping train ViT on smaller datasets.
SegFormer (2021) by Xie et al.: Uses a lightweight MLP decoder to aggregate multi-scale features across the model’s layers, improving segmentation performance while achieving efficiency gains over traditional CNN-based segmentation models.
Conclusion
The rise of Vision Transformers (ViTs) marks a revolutionary shift in computer vision, challenging the long-standing dominance of Convolutional Neural Networks (CNNs). With their unique ability to process images globally and holistically through self-attention, ViTs have demonstrated remarkable scalability and performance, particularly in handling large datasets and high-resolution photos.
Vision Transformers and their derivatives are poised to remain at the forefront of computer vision research and applications. With ongoing developments to enhance their efficiency and effectiveness, the field will continue to evolve, offering new opportunities for innovation and application.
Written by

Aryan Kargwal
Data Evangelist



Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.