LLMs
Deploying LLMs as an API Endpoint with Tune Studio
May 9, 2024
4 min read

In the modern landscape of Big Data and Automation, one must be tempted to check out this magical thing called Large Language Models. This seemingly magical first step towards Artificial General Intelligence has intrigued the industry, and you should jump into the action! What better way to do so than by deploying your own large language models as an API endpoint to Tinker and pairing them up with any web or mobile application of choice?
Challenges of Deploying LLMs
Before getting into the technical implementation of deploying an LLM using an API endpoint, let us look at some of the challenges that come with deploying LLMs:
Scaling Prompt Engineering: In practice, for a novel deployment of an LLM, more often than not, prompt engineering needs to be scaled for each user, which can prove to be difficult in deployments without the proper tools.
Optimization Techniques: Optimizing large language models is a time-consuming task that requires multiple variations of the base model on the custom dataset, prompt engineering criteria, and model behavior.
Latency: The critically acclaimed APIs and Legacy models available are often overkill for the tasks we are trying to achieve and simply don’t provide good enough alternatives and possibilities for making inferences faster.
Specifically, in the case of large language models, if you have a keen mind and interest in the workings of different LLMs, such endpoints make communication with the large black boxes of code present in the form of GPTs or LLaMAs easier for your end user not to learn command line and programming to get results from the model. Now, let’s examine how to avoid these challenges and easily deploy large language models on Tune Studio!
Deploying LLMs as an API Endpoint:
Not so adept in the command line, and the API endpoints your model provider gives you seems like a jargon? Welcome to the group, as part of our development centric approach to Large Language Models, Tune Studio comes packed with its very own UI to facilitate smoother API endpoint generation for a deployed model. Let us look at the steps to deploy your own model.
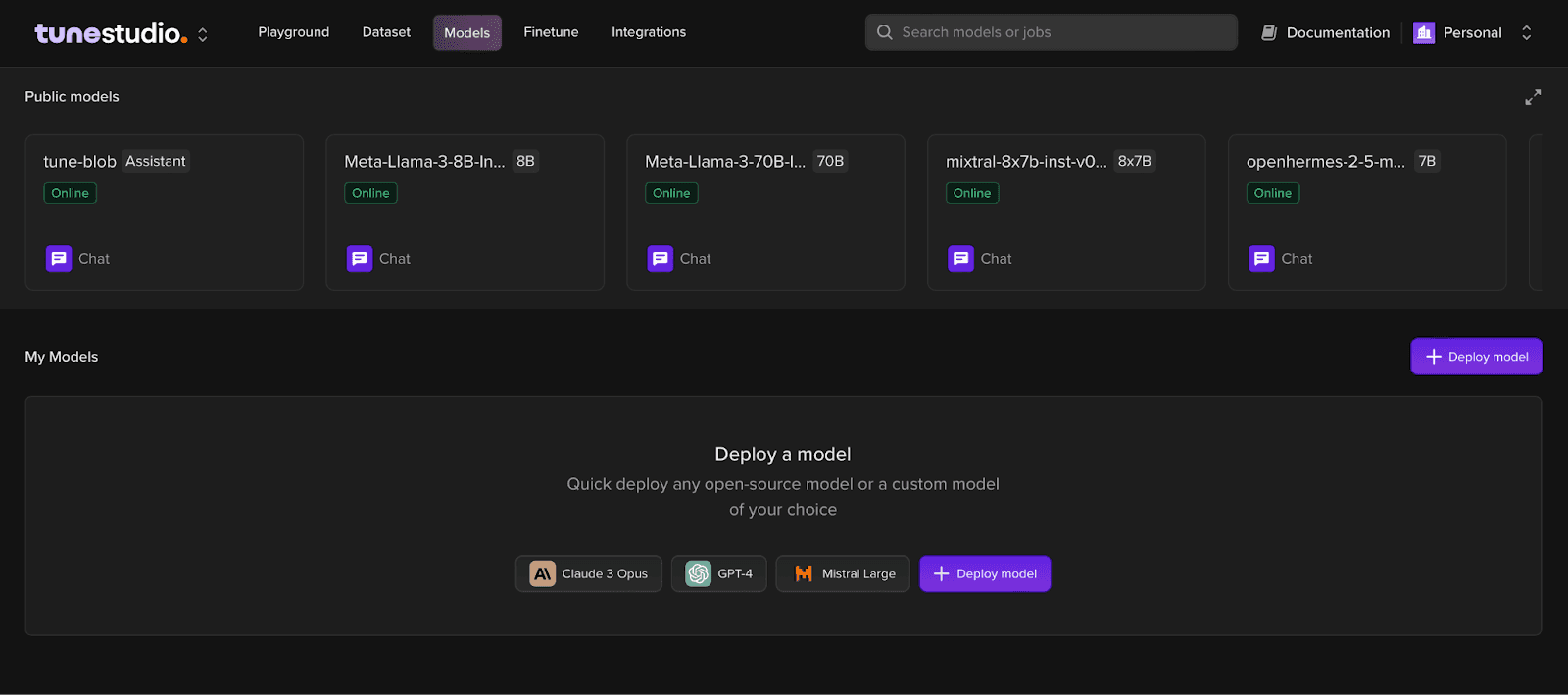
Step 1: Head over to Models on Tune Studio
Tune Studio comes jam packed with a plethora of pre-deployed public models, which housed with your own deployed models is ready for use within just 2 clicks! User can access these models through the Models Tab on Tune Studio.
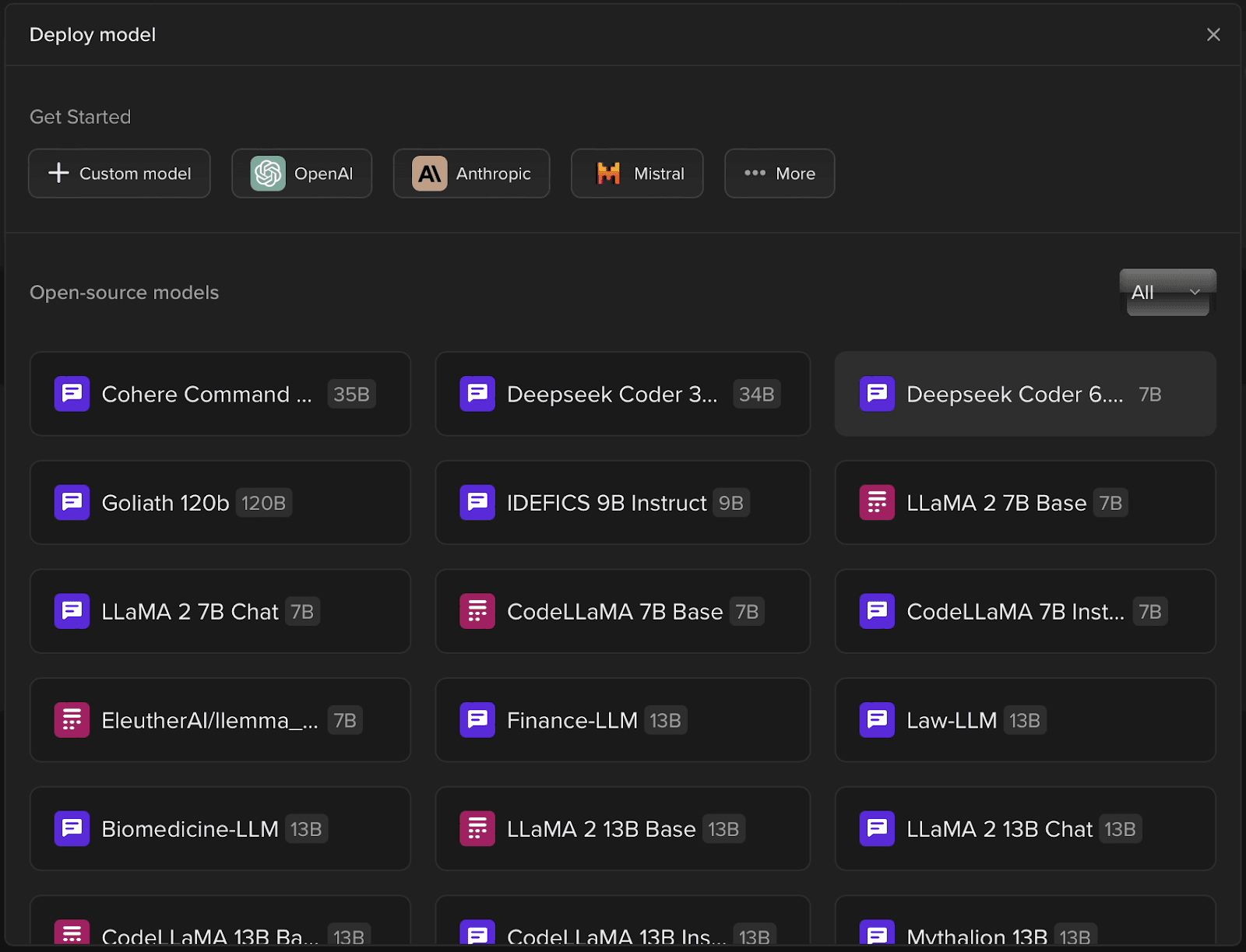
Step 2: Select the Model to be Deployed
Not looking to play around with any of our pre-deployed models? How about deploying your very own Open-Source Model or a Custom Model or any of the foundational models by enterprise developers such as Claude, GPT, Mistral, Groq or Hugging Face?
Step 3: Head over to Deployed Model
Once the model is deployed all the pre-deployed and your own deployed model is available for use on the “Models” page, head over to the model of choice.
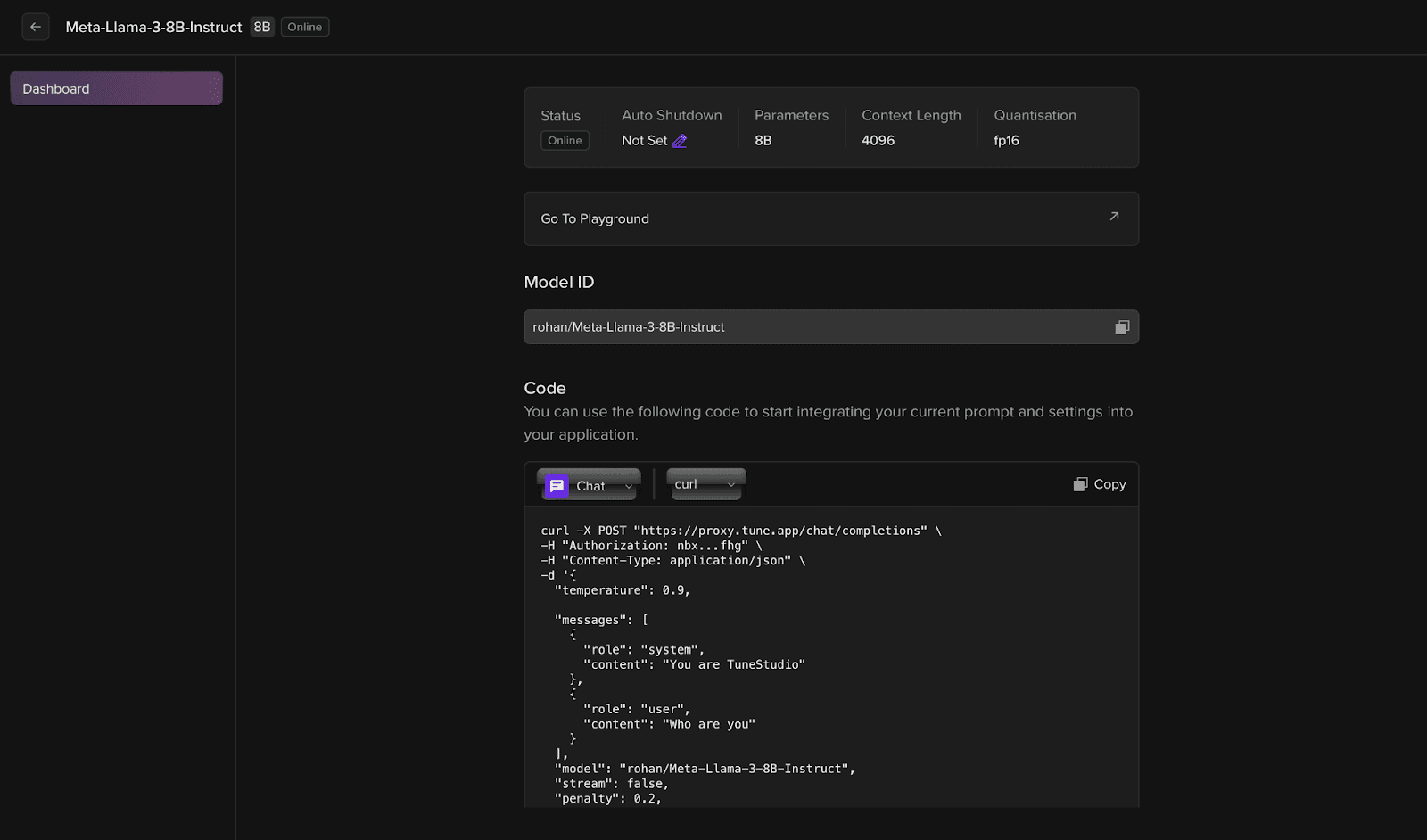
Step 4: Copy and Run the Curl Command
Once in the model of choice, just simply copy and paste the custom curl command to deploy your model as an API Endpoint.
And voila, your custom open-source Large Language Model has been deployed on Tune Studio available as an API endpoint and locally as a service in the form of Tune Studio Playground.
Consuming Deployed LLMs as a Service
Deployed models can be tested on Tune Studio through Playground. To simply start consuming the deployed LLM as a service, head over to “Models” and open the Model in “Playground”. The “Playground” is designed to be a sandbox environment for your deployed model to be tinkered and perfected on fly by influencing the hyperparameters and testing it through feedback loop in form of a Chat.
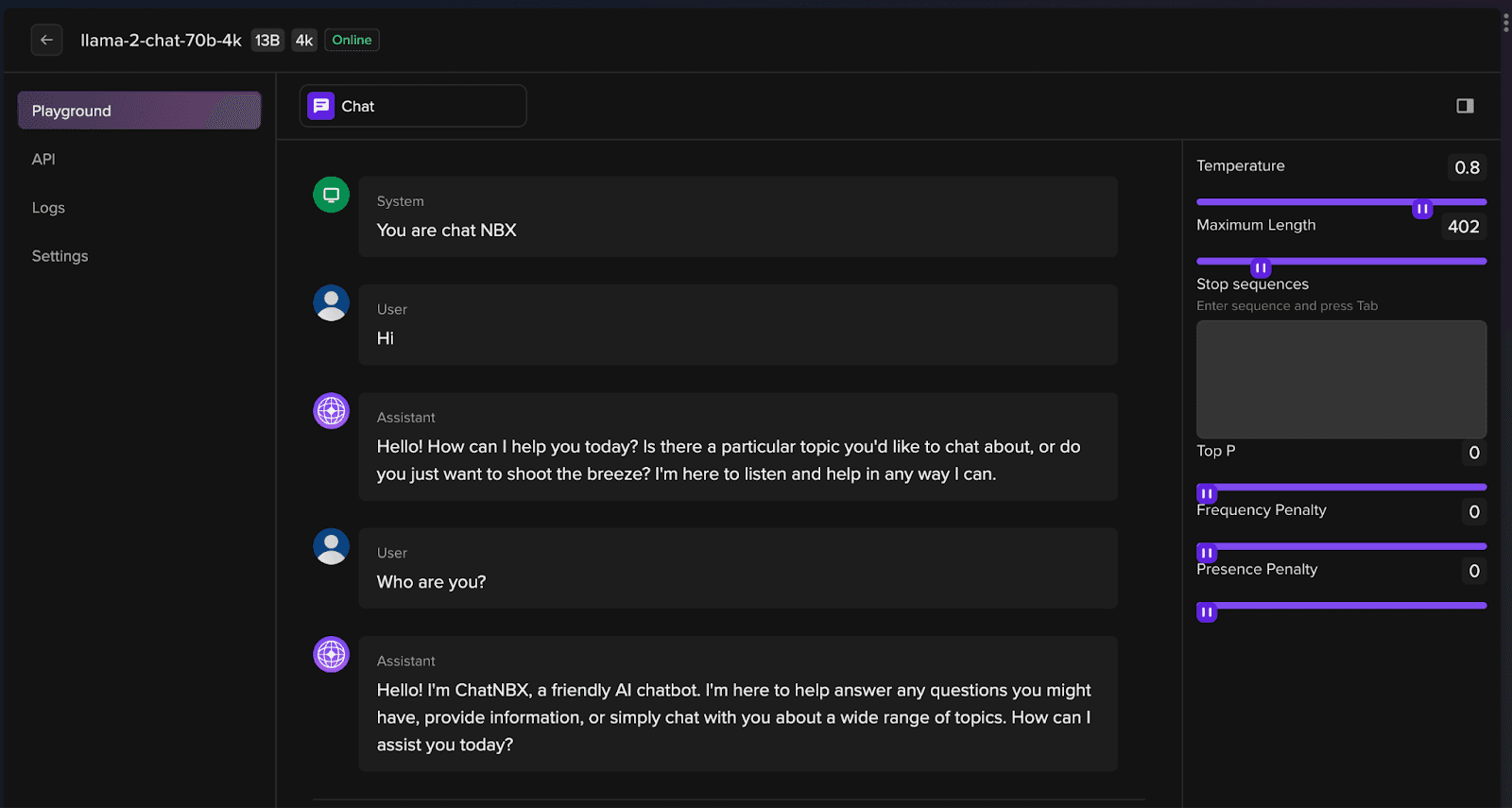
Herein, with just a simple sentence set the System Prompt for your system, and start conversing with your amazing new Large Language Model.
Conclusion
In this blog, we understood the importance of deploying API endpoints and the different challenges faced while deploying LLMs as API endpoints. We also learned the easy steps to deploy custom LLMs on-premise and elsewhere.

In the modern landscape of Big Data and Automation, one must be tempted to check out this magical thing called Large Language Models. This seemingly magical first step towards Artificial General Intelligence has intrigued the industry, and you should jump into the action! What better way to do so than by deploying your own large language models as an API endpoint to Tinker and pairing them up with any web or mobile application of choice?
Challenges of Deploying LLMs
Before getting into the technical implementation of deploying an LLM using an API endpoint, let us look at some of the challenges that come with deploying LLMs:
Scaling Prompt Engineering: In practice, for a novel deployment of an LLM, more often than not, prompt engineering needs to be scaled for each user, which can prove to be difficult in deployments without the proper tools.
Optimization Techniques: Optimizing large language models is a time-consuming task that requires multiple variations of the base model on the custom dataset, prompt engineering criteria, and model behavior.
Latency: The critically acclaimed APIs and Legacy models available are often overkill for the tasks we are trying to achieve and simply don’t provide good enough alternatives and possibilities for making inferences faster.
Specifically, in the case of large language models, if you have a keen mind and interest in the workings of different LLMs, such endpoints make communication with the large black boxes of code present in the form of GPTs or LLaMAs easier for your end user not to learn command line and programming to get results from the model. Now, let’s examine how to avoid these challenges and easily deploy large language models on Tune Studio!
Deploying LLMs as an API Endpoint:
Not so adept in the command line, and the API endpoints your model provider gives you seems like a jargon? Welcome to the group, as part of our development centric approach to Large Language Models, Tune Studio comes packed with its very own UI to facilitate smoother API endpoint generation for a deployed model. Let us look at the steps to deploy your own model.
Step 1: Head over to Models on Tune Studio
Tune Studio comes jam packed with a plethora of pre-deployed public models, which housed with your own deployed models is ready for use within just 2 clicks! User can access these models through the Models Tab on Tune Studio.
Step 2: Select the Model to be Deployed
Not looking to play around with any of our pre-deployed models? How about deploying your very own Open-Source Model or a Custom Model or any of the foundational models by enterprise developers such as Claude, GPT, Mistral, Groq or Hugging Face?
Step 3: Head over to Deployed Model
Once the model is deployed all the pre-deployed and your own deployed model is available for use on the “Models” page, head over to the model of choice.
Step 4: Copy and Run the Curl Command
Once in the model of choice, just simply copy and paste the custom curl command to deploy your model as an API Endpoint.
And voila, your custom open-source Large Language Model has been deployed on Tune Studio available as an API endpoint and locally as a service in the form of Tune Studio Playground.
Consuming Deployed LLMs as a Service
Deployed models can be tested on Tune Studio through Playground. To simply start consuming the deployed LLM as a service, head over to “Models” and open the Model in “Playground”. The “Playground” is designed to be a sandbox environment for your deployed model to be tinkered and perfected on fly by influencing the hyperparameters and testing it through feedback loop in form of a Chat.
Herein, with just a simple sentence set the System Prompt for your system, and start conversing with your amazing new Large Language Model.
Conclusion
In this blog, we understood the importance of deploying API endpoints and the different challenges faced while deploying LLMs as API endpoints. We also learned the easy steps to deploy custom LLMs on-premise and elsewhere.
In the modern landscape of Big Data and Automation, one must be tempted to check out this magical thing called Large Language Models. This seemingly magical first step towards Artificial General Intelligence has intrigued the industry, and you should jump into the action! What better way to do so than by deploying your own large language models as an API endpoint to Tinker and pairing them up with any web or mobile application of choice?
Challenges of Deploying LLMs
Before getting into the technical implementation of deploying an LLM using an API endpoint, let us look at some of the challenges that come with deploying LLMs:
Scaling Prompt Engineering: In practice, for a novel deployment of an LLM, more often than not, prompt engineering needs to be scaled for each user, which can prove to be difficult in deployments without the proper tools.
Optimization Techniques: Optimizing large language models is a time-consuming task that requires multiple variations of the base model on the custom dataset, prompt engineering criteria, and model behavior.
Latency: The critically acclaimed APIs and Legacy models available are often overkill for the tasks we are trying to achieve and simply don’t provide good enough alternatives and possibilities for making inferences faster.
Specifically, in the case of large language models, if you have a keen mind and interest in the workings of different LLMs, such endpoints make communication with the large black boxes of code present in the form of GPTs or LLaMAs easier for your end user not to learn command line and programming to get results from the model. Now, let’s examine how to avoid these challenges and easily deploy large language models on Tune Studio!
Deploying LLMs as an API Endpoint:
Not so adept in the command line, and the API endpoints your model provider gives you seems like a jargon? Welcome to the group, as part of our development centric approach to Large Language Models, Tune Studio comes packed with its very own UI to facilitate smoother API endpoint generation for a deployed model. Let us look at the steps to deploy your own model.
Step 1: Head over to Models on Tune Studio
Tune Studio comes jam packed with a plethora of pre-deployed public models, which housed with your own deployed models is ready for use within just 2 clicks! User can access these models through the Models Tab on Tune Studio.
Step 2: Select the Model to be Deployed
Not looking to play around with any of our pre-deployed models? How about deploying your very own Open-Source Model or a Custom Model or any of the foundational models by enterprise developers such as Claude, GPT, Mistral, Groq or Hugging Face?
Step 3: Head over to Deployed Model
Once the model is deployed all the pre-deployed and your own deployed model is available for use on the “Models” page, head over to the model of choice.
Step 4: Copy and Run the Curl Command
Once in the model of choice, just simply copy and paste the custom curl command to deploy your model as an API Endpoint.
And voila, your custom open-source Large Language Model has been deployed on Tune Studio available as an API endpoint and locally as a service in the form of Tune Studio Playground.
Consuming Deployed LLMs as a Service
Deployed models can be tested on Tune Studio through Playground. To simply start consuming the deployed LLM as a service, head over to “Models” and open the Model in “Playground”. The “Playground” is designed to be a sandbox environment for your deployed model to be tinkered and perfected on fly by influencing the hyperparameters and testing it through feedback loop in form of a Chat.
Herein, with just a simple sentence set the System Prompt for your system, and start conversing with your amazing new Large Language Model.
Conclusion
In this blog, we understood the importance of deploying API endpoints and the different challenges faced while deploying LLMs as API endpoints. We also learned the easy steps to deploy custom LLMs on-premise and elsewhere.
Written by

Aryan Kargwal
Data Evangelist
Edited by

Chandrani Halder
Head of Product


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.