LLMs
Exploring Claude as a GenAI Developer
Nov 4, 2024
5 min read

Anthropic’s New Groundbreaking announcements are much more than the clickbait “Anthropic Can Control your Computer” circulating online and in newsletters. What are these new announcements, what new level of performance do general developers expect from these models, and most importantly, what is the cost? In this blog, we shall look at all of them and assess whether Claude, by Anthropic stands true.
Groundbreaking “Computer Use”
Indeed, among the carousels of information and content about the model and the announcement, one that catches everyone’s attention is the “Computer Use” feature that comes into Claude. This feature allows the model to interact directly with your desktop, unlocking a new sense of autonomy and control. The feature, however, is not new and has been achieved by the likes of Microsoft Co-Pilot, Rabbit R1, or Open Interpreter’s 01. What makes it different? Well, Claude does!
Where most “AI Assistants”, open source or closed, were hasty in giving their Language models every permission on the planet to get a mediocre, hallucinating monster that constantly sends back your data to shady developers with barely any actual results and hardcoded UI-based instructions that need to update every time Instagram decides that the share button is too easy to find and needs to go under two more layers of options, Claude took its time, figured policies that can be generalized over systems, and work seamlessly with major operating system workflows.
Command Translation: The "computer use" API breaks down high-level instructions into detailed action sequences executable on standard operating systems. Each command is validated for compatibility across Windows, macOS, and Linux interfaces, providing a universal solution for desktop automation.
Context Awareness and State Management: One of the most advanced aspects of this feature is its ability to maintain context within application environments. For instance, Claude can remember file directories accessed, manage tabs in web browsers, and switch between applications without losing their place, adding immense value for multi-application workflows.
Early-Stage Beta Limitations and Considerations: Certain limitations apply as this capability is in beta, such as a finite range of executable commands and restricted toolsets. However, Anthropic has designed this feature with a modular approach, ensuring that additional functionalities can be integrated over time, such as enhanced compatibility with domain-specific software (e.g., financial or engineering applications).
By taking instructions and translating them into executable commands on a virtual desktop, Claude can assist with various workflows, including file navigation, application handling, and automation of UI interactions.
Claude 3.5 Sonnet
Designed to surpass the capabilities of earlier Claude models, Sonnet excels in coding efficiency, command interpretation, and tool use. Benchmarked across standard tests like SWE-bench and TAU-bench, Claude 3.5 Sonnet showcases an improved capacity to manage complex, multi-step code generation tasks.

Critical advancements in Sonnet include:
Tool Use Proficiency: Claude 3.5 Sonnet has been optimized for the effective use of development tools, demonstrating smoother integration with code editors, CLIs, and coding IDEs.
Coding Context Management: It supports longer context windows, facilitating multi-file project handling and maintaining semantic understanding across extensive codebases. This is crucial for debugging and code refactoring.
The Claude 3.5 Sonnet model substantially improves technical benchmarks, scoring 54.3% on the SWE bench and 86.7% on the TAU bench, critical metrics for evaluating coding and task automation performance. These scores show enhanced capabilities compared to Claude 3 Opus.
Claude 3.5 Haiku
Unlike Claude 3 Opus, which is optimised for complex, large-scale deployments or even Sonet, Haiku focuses on affordability without compromising much on performance, making it ideal for user-facing applications. More benchmarks and information about this model will be available soon as the model is launched later this year.
Notable characteristics of Haiku include:
Optimized Latency: Haiku’s architecture is tuned for fast response times, catering to applications where real-time interaction is vital.
Enhanced Task Specialization: This model is particularly adept at tasks like database queries, API integration, and short-code generation, making it suitable for chatbot and customer service roles.
Let us look at the pricing differences to understand the difference between the models and the pricing competition the model provides against other SOTA.
Pricing
Moving on to the pricing for the models, let us compare them to their “OpenAI Counterparts.” Regarding size and affordability, Haiku is directly comparable to 4o Mini, Sonnet to 4o, and Opus to O1. Now, on first look, the pricing may feel acute and quite similar; let us try to break it down to understand where exactly the difference is.
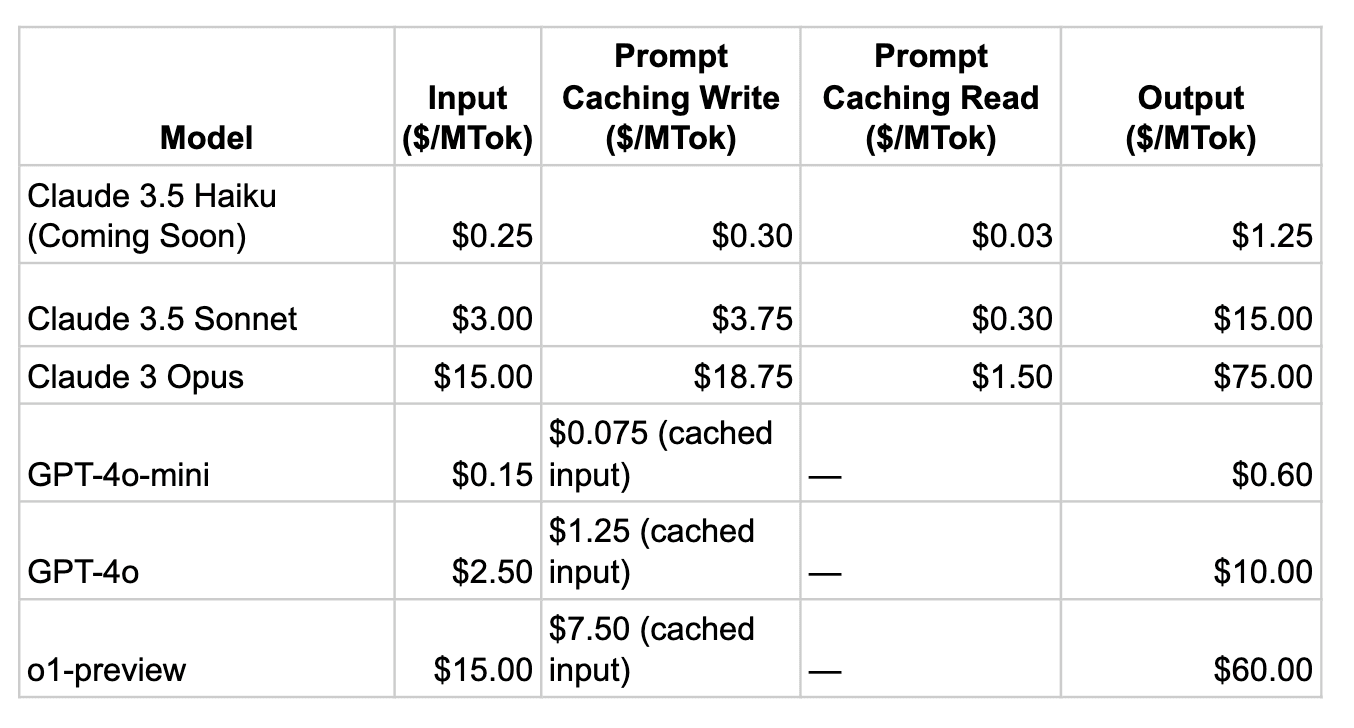
When talking about AI assistants, especially those deployed on a mass scale, the pricing effectiveness of your model just boils down to how expensive or inexpensively the model can handle repeated tasks and queries. In this regard, Anthropic emerges as the winner because it utilises a caching system that significantly reduces costs associated with frequent interactions.
By implementing both write and read caching, Anthropic allows businesses to cache input tokens at a slightly higher initial cost ($0.30 per million tokens for write caching) while enabling a dramatically lower cost for read caching ($0.03 per million tokens for repeated queries). This tiered pricing structure provides substantial savings for companies that regularly use the same prompts, making it especially appealing for high-traffic applications where efficiency is critical.
In contrast, while effective, OpenAI's caching mechanism lacks the same granularity in pricing. OpenAI offers a flat rate for cached prompts, such as $1.25 per million tokens for reused inputs with their GPT-4o model. Although 50% less than the standard input cost, it doesn’t offer the same significant reduction for repeated queries as Anthropic’s read caching. For businesses managing numerous repetitive tasks, the cumulative cost can be notably higher with OpenAI, potentially impacting budget allocations for AI projects.
Conclusion
As developers and businesses consider integrating AI assistants into their operations, Anthropic's Claude presents a compelling case. With its focus on effective cost management, advanced functionality, and adaptability to diverse applications, Claude lives up to the hype and challenges the status quo in the AI space.
Moreover, the pricing structure of Anthropic's models, especially the Haiku and Sonnet versions, showcases a strategic focus on affordability without compromising performance. By leveraging a tiered caching system that dramatically reduces costs for repeated queries, Anthropic offers businesses a cost-effective solution for handling high-frequency interactions.
Further Reading
Anthropic’s New Groundbreaking announcements are much more than the clickbait “Anthropic Can Control your Computer” circulating online and in newsletters. What are these new announcements, what new level of performance do general developers expect from these models, and most importantly, what is the cost? In this blog, we shall look at all of them and assess whether Claude, by Anthropic stands true.
Groundbreaking “Computer Use”
Indeed, among the carousels of information and content about the model and the announcement, one that catches everyone’s attention is the “Computer Use” feature that comes into Claude. This feature allows the model to interact directly with your desktop, unlocking a new sense of autonomy and control. The feature, however, is not new and has been achieved by the likes of Microsoft Co-Pilot, Rabbit R1, or Open Interpreter’s 01. What makes it different? Well, Claude does!
Where most “AI Assistants”, open source or closed, were hasty in giving their Language models every permission on the planet to get a mediocre, hallucinating monster that constantly sends back your data to shady developers with barely any actual results and hardcoded UI-based instructions that need to update every time Instagram decides that the share button is too easy to find and needs to go under two more layers of options, Claude took its time, figured policies that can be generalized over systems, and work seamlessly with major operating system workflows.
Command Translation: The "computer use" API breaks down high-level instructions into detailed action sequences executable on standard operating systems. Each command is validated for compatibility across Windows, macOS, and Linux interfaces, providing a universal solution for desktop automation.
Context Awareness and State Management: One of the most advanced aspects of this feature is its ability to maintain context within application environments. For instance, Claude can remember file directories accessed, manage tabs in web browsers, and switch between applications without losing their place, adding immense value for multi-application workflows.
Early-Stage Beta Limitations and Considerations: Certain limitations apply as this capability is in beta, such as a finite range of executable commands and restricted toolsets. However, Anthropic has designed this feature with a modular approach, ensuring that additional functionalities can be integrated over time, such as enhanced compatibility with domain-specific software (e.g., financial or engineering applications).
By taking instructions and translating them into executable commands on a virtual desktop, Claude can assist with various workflows, including file navigation, application handling, and automation of UI interactions.
Claude 3.5 Sonnet
Designed to surpass the capabilities of earlier Claude models, Sonnet excels in coding efficiency, command interpretation, and tool use. Benchmarked across standard tests like SWE-bench and TAU-bench, Claude 3.5 Sonnet showcases an improved capacity to manage complex, multi-step code generation tasks.
Critical advancements in Sonnet include:
Tool Use Proficiency: Claude 3.5 Sonnet has been optimized for the effective use of development tools, demonstrating smoother integration with code editors, CLIs, and coding IDEs.
Coding Context Management: It supports longer context windows, facilitating multi-file project handling and maintaining semantic understanding across extensive codebases. This is crucial for debugging and code refactoring.
The Claude 3.5 Sonnet model substantially improves technical benchmarks, scoring 54.3% on the SWE bench and 86.7% on the TAU bench, critical metrics for evaluating coding and task automation performance. These scores show enhanced capabilities compared to Claude 3 Opus.
Claude 3.5 Haiku
Unlike Claude 3 Opus, which is optimised for complex, large-scale deployments or even Sonet, Haiku focuses on affordability without compromising much on performance, making it ideal for user-facing applications. More benchmarks and information about this model will be available soon as the model is launched later this year.
Notable characteristics of Haiku include:
Optimized Latency: Haiku’s architecture is tuned for fast response times, catering to applications where real-time interaction is vital.
Enhanced Task Specialization: This model is particularly adept at tasks like database queries, API integration, and short-code generation, making it suitable for chatbot and customer service roles.
Let us look at the pricing differences to understand the difference between the models and the pricing competition the model provides against other SOTA.
Pricing
Moving on to the pricing for the models, let us compare them to their “OpenAI Counterparts.” Regarding size and affordability, Haiku is directly comparable to 4o Mini, Sonnet to 4o, and Opus to O1. Now, on first look, the pricing may feel acute and quite similar; let us try to break it down to understand where exactly the difference is.
When talking about AI assistants, especially those deployed on a mass scale, the pricing effectiveness of your model just boils down to how expensive or inexpensively the model can handle repeated tasks and queries. In this regard, Anthropic emerges as the winner because it utilises a caching system that significantly reduces costs associated with frequent interactions.
By implementing both write and read caching, Anthropic allows businesses to cache input tokens at a slightly higher initial cost ($0.30 per million tokens for write caching) while enabling a dramatically lower cost for read caching ($0.03 per million tokens for repeated queries). This tiered pricing structure provides substantial savings for companies that regularly use the same prompts, making it especially appealing for high-traffic applications where efficiency is critical.
In contrast, while effective, OpenAI's caching mechanism lacks the same granularity in pricing. OpenAI offers a flat rate for cached prompts, such as $1.25 per million tokens for reused inputs with their GPT-4o model. Although 50% less than the standard input cost, it doesn’t offer the same significant reduction for repeated queries as Anthropic’s read caching. For businesses managing numerous repetitive tasks, the cumulative cost can be notably higher with OpenAI, potentially impacting budget allocations for AI projects.
Conclusion
As developers and businesses consider integrating AI assistants into their operations, Anthropic's Claude presents a compelling case. With its focus on effective cost management, advanced functionality, and adaptability to diverse applications, Claude lives up to the hype and challenges the status quo in the AI space.
Moreover, the pricing structure of Anthropic's models, especially the Haiku and Sonnet versions, showcases a strategic focus on affordability without compromising performance. By leveraging a tiered caching system that dramatically reduces costs for repeated queries, Anthropic offers businesses a cost-effective solution for handling high-frequency interactions.
Further Reading
Anthropic’s New Groundbreaking announcements are much more than the clickbait “Anthropic Can Control your Computer” circulating online and in newsletters. What are these new announcements, what new level of performance do general developers expect from these models, and most importantly, what is the cost? In this blog, we shall look at all of them and assess whether Claude, by Anthropic stands true.
Groundbreaking “Computer Use”
Indeed, among the carousels of information and content about the model and the announcement, one that catches everyone’s attention is the “Computer Use” feature that comes into Claude. This feature allows the model to interact directly with your desktop, unlocking a new sense of autonomy and control. The feature, however, is not new and has been achieved by the likes of Microsoft Co-Pilot, Rabbit R1, or Open Interpreter’s 01. What makes it different? Well, Claude does!
Where most “AI Assistants”, open source or closed, were hasty in giving their Language models every permission on the planet to get a mediocre, hallucinating monster that constantly sends back your data to shady developers with barely any actual results and hardcoded UI-based instructions that need to update every time Instagram decides that the share button is too easy to find and needs to go under two more layers of options, Claude took its time, figured policies that can be generalized over systems, and work seamlessly with major operating system workflows.
Command Translation: The "computer use" API breaks down high-level instructions into detailed action sequences executable on standard operating systems. Each command is validated for compatibility across Windows, macOS, and Linux interfaces, providing a universal solution for desktop automation.
Context Awareness and State Management: One of the most advanced aspects of this feature is its ability to maintain context within application environments. For instance, Claude can remember file directories accessed, manage tabs in web browsers, and switch between applications without losing their place, adding immense value for multi-application workflows.
Early-Stage Beta Limitations and Considerations: Certain limitations apply as this capability is in beta, such as a finite range of executable commands and restricted toolsets. However, Anthropic has designed this feature with a modular approach, ensuring that additional functionalities can be integrated over time, such as enhanced compatibility with domain-specific software (e.g., financial or engineering applications).
By taking instructions and translating them into executable commands on a virtual desktop, Claude can assist with various workflows, including file navigation, application handling, and automation of UI interactions.
Claude 3.5 Sonnet
Designed to surpass the capabilities of earlier Claude models, Sonnet excels in coding efficiency, command interpretation, and tool use. Benchmarked across standard tests like SWE-bench and TAU-bench, Claude 3.5 Sonnet showcases an improved capacity to manage complex, multi-step code generation tasks.
Critical advancements in Sonnet include:
Tool Use Proficiency: Claude 3.5 Sonnet has been optimized for the effective use of development tools, demonstrating smoother integration with code editors, CLIs, and coding IDEs.
Coding Context Management: It supports longer context windows, facilitating multi-file project handling and maintaining semantic understanding across extensive codebases. This is crucial for debugging and code refactoring.
The Claude 3.5 Sonnet model substantially improves technical benchmarks, scoring 54.3% on the SWE bench and 86.7% on the TAU bench, critical metrics for evaluating coding and task automation performance. These scores show enhanced capabilities compared to Claude 3 Opus.
Claude 3.5 Haiku
Unlike Claude 3 Opus, which is optimised for complex, large-scale deployments or even Sonet, Haiku focuses on affordability without compromising much on performance, making it ideal for user-facing applications. More benchmarks and information about this model will be available soon as the model is launched later this year.
Notable characteristics of Haiku include:
Optimized Latency: Haiku’s architecture is tuned for fast response times, catering to applications where real-time interaction is vital.
Enhanced Task Specialization: This model is particularly adept at tasks like database queries, API integration, and short-code generation, making it suitable for chatbot and customer service roles.
Let us look at the pricing differences to understand the difference between the models and the pricing competition the model provides against other SOTA.
Pricing
Moving on to the pricing for the models, let us compare them to their “OpenAI Counterparts.” Regarding size and affordability, Haiku is directly comparable to 4o Mini, Sonnet to 4o, and Opus to O1. Now, on first look, the pricing may feel acute and quite similar; let us try to break it down to understand where exactly the difference is.
When talking about AI assistants, especially those deployed on a mass scale, the pricing effectiveness of your model just boils down to how expensive or inexpensively the model can handle repeated tasks and queries. In this regard, Anthropic emerges as the winner because it utilises a caching system that significantly reduces costs associated with frequent interactions.
By implementing both write and read caching, Anthropic allows businesses to cache input tokens at a slightly higher initial cost ($0.30 per million tokens for write caching) while enabling a dramatically lower cost for read caching ($0.03 per million tokens for repeated queries). This tiered pricing structure provides substantial savings for companies that regularly use the same prompts, making it especially appealing for high-traffic applications where efficiency is critical.
In contrast, while effective, OpenAI's caching mechanism lacks the same granularity in pricing. OpenAI offers a flat rate for cached prompts, such as $1.25 per million tokens for reused inputs with their GPT-4o model. Although 50% less than the standard input cost, it doesn’t offer the same significant reduction for repeated queries as Anthropic’s read caching. For businesses managing numerous repetitive tasks, the cumulative cost can be notably higher with OpenAI, potentially impacting budget allocations for AI projects.
Conclusion
As developers and businesses consider integrating AI assistants into their operations, Anthropic's Claude presents a compelling case. With its focus on effective cost management, advanced functionality, and adaptability to diverse applications, Claude lives up to the hype and challenges the status quo in the AI space.
Moreover, the pricing structure of Anthropic's models, especially the Haiku and Sonnet versions, showcases a strategic focus on affordability without compromising performance. By leveraging a tiered caching system that dramatically reduces costs for repeated queries, Anthropic offers businesses a cost-effective solution for handling high-frequency interactions.
Further Reading
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.