LLMs
Finetuning Llama 3.1 8B using Adapters on Tune Studio
Sep 5, 2024
5 min read

As models grow larger, their knowledge corpus expands, but does that necessarily mean they're getting better? Not entirely. While bigger models may have more general knowledge, they can struggle to provide relevant, localised information without additional fine-tuning. This is where fine-tuning becomes crucial. Fine-tuning allows for domain-specific knowledge transfer, enabling models to perform better in specialized areas. It's not just about making large models brighter. It's also about adapting smaller models to suit your needs and effectively incorporating your biases and preferences into the model’s output.
Finetuning, or more specifically, Finetuning using Adapters, is the thing of the future as more and more developers and companies move towards this method to safeguard and idiot-proof their LLM and GenAI pipelines. In this blog, we will check out all about adapters and how you can utilise Tune Studio to Finetune your GenAI model on the custom dataset using Adapters.
Need for Adapters
Before diving deeper, adapters are lightweight modules inserted into large language model architectures to enable the model to be fine-tuned to minute details and tasks without altering the inherent architecture. The need for such modules arose from the various shortcomings of traditional finetuning methods:
1. High Computational Cost: Costs range as the model eats away at processing trying to change the dataset.
2. Storage Requirements: Each model iteration needs to be stored separately and is as big as the models.
3. Catastrophic Amnesia: Big models tend to forget performance on various previous tasks on which they were trained.
Adapters counter these challenges by making them more parameter-efficient and modular while retaining their previous knowledge. With the initial idea behind traditional fine-tuning still present, Adapters works by introducing tunable layers to the various transformer blocks in traditional LLMs, which works wonders more than tweaking your input in the model to achieve a more “Fine” result. Adapters push the boundaries of scalability with the ability to load hundreds if not thousands of adapters using techniques such as S-LoRA on a single server GPU.
How Adapters Work
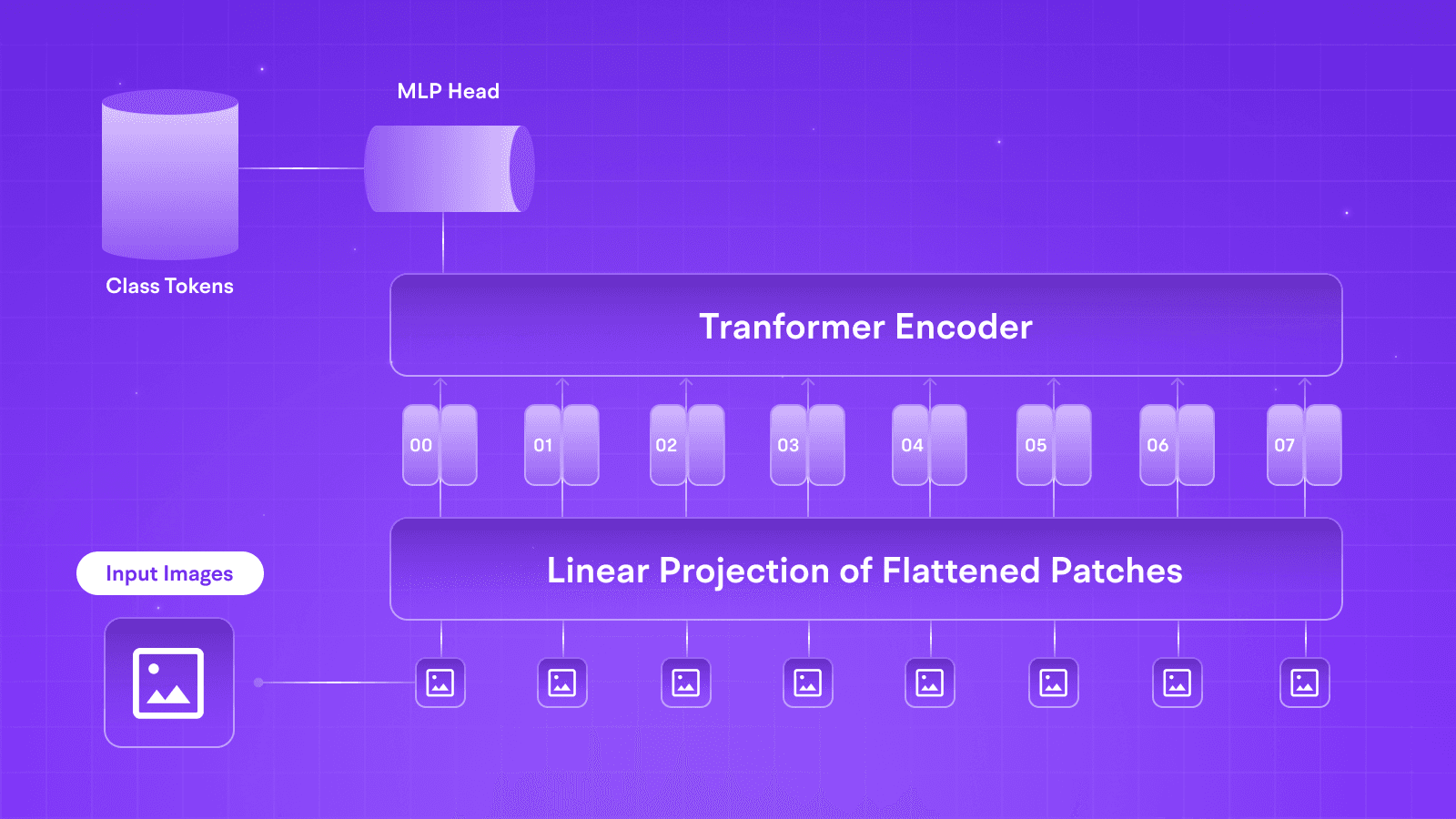
Adapters are small neural networks inserted in the layers of a pre-trained LLM, such as Llama 3.1. These modules work with three essential elements:
1. Down-Projection Layer: This layer reduces the dimensionality of the input by projecting it into a lower dimensional space.
2. Non-Linear Activation: A non-linear activation function like ReLU is applied to introduce non-linearity.
3. Up-Projection Layer: The output is projected in original dimensionality, allowing it to integrate within the primary model’s representations.
These modules act as bottlenecks in the architecture, much like an autoencoder, and are inserted between multi-head self-attention and feed-forward layers, ensuring that weights in those layers are not updated but only the adapters.

During inference, these fine-tuned adapters are activated in the model, modifying the representations as they pass through the network layers. This complimenting of pre-existing and fine-tuned knowledge enables the model to perform well on the task it was fine-tuned for.
Finetuning using Adapters on Tune Studio
Using adapters, let us examine how to fine-tune Llama 3.1 8B on Tune Studio. For the sake of this tutorial, you just need to head over to Tune Studio and sign up; the free credits are surely enough for you to run dozens of Adapter Jobs.

Firstly, we will head to the Finetune tab on Tune Studio and Add a new Finetuning Job.

Once the model is named, users can choose the model they want to fine-tune using Adapters.
Note: Finetuning on Tune Studio UI using adapters is only available on Two Models; however, to Finetune more Models without Adapters, use our API.

Users can then choose the dataset of their choice or upload it from any external source through our UI. For more information, check out Tune API Documentation. The dataset that we are looking for should be in the following format.
{"conversations": [{"role": "system", "content": "Marv: your go-to chatbot for facts with attitude."}, {"role": "human", "content": "What's the largest planet in our solar system?"}, {"role": "gpt", "content": "Ugh, really? You don't know this? Fine. It's Jupiter. Happy now?" }]}
{"conversations": [{"role": "system", "content": "Marv: your go-to chatbot for facts with attitude."}, {"role": "human", "content": "Who painted 'The Starry Night'?"}, {"role": "gpt", "content": "Sigh... It was Vincent van Gogh. Next thing you'll ask me who painted the Mona Lisa..."}]}
{"role": "human", "content": "What's the capital of Australia?"}, {"role": "gpt", "content": "Really? You didn't know this one? Canberra... Don't worry,I won't tell anyone." }]}

Once we have chosen the dataset, users can tweak many fine-tuning parameters, such as the Cloud you want to use, Tune AI, or BYOC (Bring Your Own Cloud, link Tune Studio with any of your chosen cloud services). We can also record the weights and parameters of the ongoing finetuning as Checkpoints on any external source.

Once the model has been fine-tuned, it can easily be opened in the playground for experimentation. Once trained, the model will be available for further use, which can be further accentuated using the Tune API.
Conclusion
In Summary, we saw that adapters in transformers are improving the way we fine-tune GenAI models. By focusing on a small set of parameters, we trim down the fine-tuning costs for the models with the slightest change to the inherent knowledge corpus of the intelligent large language model.
As models grow larger, their knowledge corpus expands, but does that necessarily mean they're getting better? Not entirely. While bigger models may have more general knowledge, they can struggle to provide relevant, localised information without additional fine-tuning. This is where fine-tuning becomes crucial. Fine-tuning allows for domain-specific knowledge transfer, enabling models to perform better in specialized areas. It's not just about making large models brighter. It's also about adapting smaller models to suit your needs and effectively incorporating your biases and preferences into the model’s output.
Finetuning, or more specifically, Finetuning using Adapters, is the thing of the future as more and more developers and companies move towards this method to safeguard and idiot-proof their LLM and GenAI pipelines. In this blog, we will check out all about adapters and how you can utilise Tune Studio to Finetune your GenAI model on the custom dataset using Adapters.
Need for Adapters
Before diving deeper, adapters are lightweight modules inserted into large language model architectures to enable the model to be fine-tuned to minute details and tasks without altering the inherent architecture. The need for such modules arose from the various shortcomings of traditional finetuning methods:
1. High Computational Cost: Costs range as the model eats away at processing trying to change the dataset.
2. Storage Requirements: Each model iteration needs to be stored separately and is as big as the models.
3. Catastrophic Amnesia: Big models tend to forget performance on various previous tasks on which they were trained.
Adapters counter these challenges by making them more parameter-efficient and modular while retaining their previous knowledge. With the initial idea behind traditional fine-tuning still present, Adapters works by introducing tunable layers to the various transformer blocks in traditional LLMs, which works wonders more than tweaking your input in the model to achieve a more “Fine” result. Adapters push the boundaries of scalability with the ability to load hundreds if not thousands of adapters using techniques such as S-LoRA on a single server GPU.
How Adapters Work
Adapters are small neural networks inserted in the layers of a pre-trained LLM, such as Llama 3.1. These modules work with three essential elements:
1. Down-Projection Layer: This layer reduces the dimensionality of the input by projecting it into a lower dimensional space.
2. Non-Linear Activation: A non-linear activation function like ReLU is applied to introduce non-linearity.
3. Up-Projection Layer: The output is projected in original dimensionality, allowing it to integrate within the primary model’s representations.
These modules act as bottlenecks in the architecture, much like an autoencoder, and are inserted between multi-head self-attention and feed-forward layers, ensuring that weights in those layers are not updated but only the adapters.
During inference, these fine-tuned adapters are activated in the model, modifying the representations as they pass through the network layers. This complimenting of pre-existing and fine-tuned knowledge enables the model to perform well on the task it was fine-tuned for.
Finetuning using Adapters on Tune Studio
Using adapters, let us examine how to fine-tune Llama 3.1 8B on Tune Studio. For the sake of this tutorial, you just need to head over to Tune Studio and sign up; the free credits are surely enough for you to run dozens of Adapter Jobs.
Firstly, we will head to the Finetune tab on Tune Studio and Add a new Finetuning Job.
Once the model is named, users can choose the model they want to fine-tune using Adapters.
Note: Finetuning on Tune Studio UI using adapters is only available on Two Models; however, to Finetune more Models without Adapters, use our API.
Users can then choose the dataset of their choice or upload it from any external source through our UI. For more information, check out Tune API Documentation. The dataset that we are looking for should be in the following format.
{"conversations": [{"role": "system", "content": "Marv: your go-to chatbot for facts with attitude."}, {"role": "human", "content": "What's the largest planet in our solar system?"}, {"role": "gpt", "content": "Ugh, really? You don't know this? Fine. It's Jupiter. Happy now?" }]}
{"conversations": [{"role": "system", "content": "Marv: your go-to chatbot for facts with attitude."}, {"role": "human", "content": "Who painted 'The Starry Night'?"}, {"role": "gpt", "content": "Sigh... It was Vincent van Gogh. Next thing you'll ask me who painted the Mona Lisa..."}]}
{"role": "human", "content": "What's the capital of Australia?"}, {"role": "gpt", "content": "Really? You didn't know this one? Canberra... Don't worry,I won't tell anyone." }]}
Once we have chosen the dataset, users can tweak many fine-tuning parameters, such as the Cloud you want to use, Tune AI, or BYOC (Bring Your Own Cloud, link Tune Studio with any of your chosen cloud services). We can also record the weights and parameters of the ongoing finetuning as Checkpoints on any external source.
Once the model has been fine-tuned, it can easily be opened in the playground for experimentation. Once trained, the model will be available for further use, which can be further accentuated using the Tune API.
Conclusion
In Summary, we saw that adapters in transformers are improving the way we fine-tune GenAI models. By focusing on a small set of parameters, we trim down the fine-tuning costs for the models with the slightest change to the inherent knowledge corpus of the intelligent large language model.
As models grow larger, their knowledge corpus expands, but does that necessarily mean they're getting better? Not entirely. While bigger models may have more general knowledge, they can struggle to provide relevant, localised information without additional fine-tuning. This is where fine-tuning becomes crucial. Fine-tuning allows for domain-specific knowledge transfer, enabling models to perform better in specialized areas. It's not just about making large models brighter. It's also about adapting smaller models to suit your needs and effectively incorporating your biases and preferences into the model’s output.
Finetuning, or more specifically, Finetuning using Adapters, is the thing of the future as more and more developers and companies move towards this method to safeguard and idiot-proof their LLM and GenAI pipelines. In this blog, we will check out all about adapters and how you can utilise Tune Studio to Finetune your GenAI model on the custom dataset using Adapters.
Need for Adapters
Before diving deeper, adapters are lightweight modules inserted into large language model architectures to enable the model to be fine-tuned to minute details and tasks without altering the inherent architecture. The need for such modules arose from the various shortcomings of traditional finetuning methods:
1. High Computational Cost: Costs range as the model eats away at processing trying to change the dataset.
2. Storage Requirements: Each model iteration needs to be stored separately and is as big as the models.
3. Catastrophic Amnesia: Big models tend to forget performance on various previous tasks on which they were trained.
Adapters counter these challenges by making them more parameter-efficient and modular while retaining their previous knowledge. With the initial idea behind traditional fine-tuning still present, Adapters works by introducing tunable layers to the various transformer blocks in traditional LLMs, which works wonders more than tweaking your input in the model to achieve a more “Fine” result. Adapters push the boundaries of scalability with the ability to load hundreds if not thousands of adapters using techniques such as S-LoRA on a single server GPU.
How Adapters Work
Adapters are small neural networks inserted in the layers of a pre-trained LLM, such as Llama 3.1. These modules work with three essential elements:
1. Down-Projection Layer: This layer reduces the dimensionality of the input by projecting it into a lower dimensional space.
2. Non-Linear Activation: A non-linear activation function like ReLU is applied to introduce non-linearity.
3. Up-Projection Layer: The output is projected in original dimensionality, allowing it to integrate within the primary model’s representations.
These modules act as bottlenecks in the architecture, much like an autoencoder, and are inserted between multi-head self-attention and feed-forward layers, ensuring that weights in those layers are not updated but only the adapters.
During inference, these fine-tuned adapters are activated in the model, modifying the representations as they pass through the network layers. This complimenting of pre-existing and fine-tuned knowledge enables the model to perform well on the task it was fine-tuned for.
Finetuning using Adapters on Tune Studio
Using adapters, let us examine how to fine-tune Llama 3.1 8B on Tune Studio. For the sake of this tutorial, you just need to head over to Tune Studio and sign up; the free credits are surely enough for you to run dozens of Adapter Jobs.
Firstly, we will head to the Finetune tab on Tune Studio and Add a new Finetuning Job.
Once the model is named, users can choose the model they want to fine-tune using Adapters.
Note: Finetuning on Tune Studio UI using adapters is only available on Two Models; however, to Finetune more Models without Adapters, use our API.
Users can then choose the dataset of their choice or upload it from any external source through our UI. For more information, check out Tune API Documentation. The dataset that we are looking for should be in the following format.
{"conversations": [{"role": "system", "content": "Marv: your go-to chatbot for facts with attitude."}, {"role": "human", "content": "What's the largest planet in our solar system?"}, {"role": "gpt", "content": "Ugh, really? You don't know this? Fine. It's Jupiter. Happy now?" }]}
{"conversations": [{"role": "system", "content": "Marv: your go-to chatbot for facts with attitude."}, {"role": "human", "content": "Who painted 'The Starry Night'?"}, {"role": "gpt", "content": "Sigh... It was Vincent van Gogh. Next thing you'll ask me who painted the Mona Lisa..."}]}
{"role": "human", "content": "What's the capital of Australia?"}, {"role": "gpt", "content": "Really? You didn't know this one? Canberra... Don't worry,I won't tell anyone." }]}
Once we have chosen the dataset, users can tweak many fine-tuning parameters, such as the Cloud you want to use, Tune AI, or BYOC (Bring Your Own Cloud, link Tune Studio with any of your chosen cloud services). We can also record the weights and parameters of the ongoing finetuning as Checkpoints on any external source.
Once the model has been fine-tuned, it can easily be opened in the playground for experimentation. Once trained, the model will be available for further use, which can be further accentuated using the Tune API.
Conclusion
In Summary, we saw that adapters in transformers are improving the way we fine-tune GenAI models. By focusing on a small set of parameters, we trim down the fine-tuning costs for the models with the slightest change to the inherent knowledge corpus of the intelligent large language model.
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.