LLMs
A DIY Guide to Finetuning LLMs with Tune Studio
May 16, 2024
2 min read
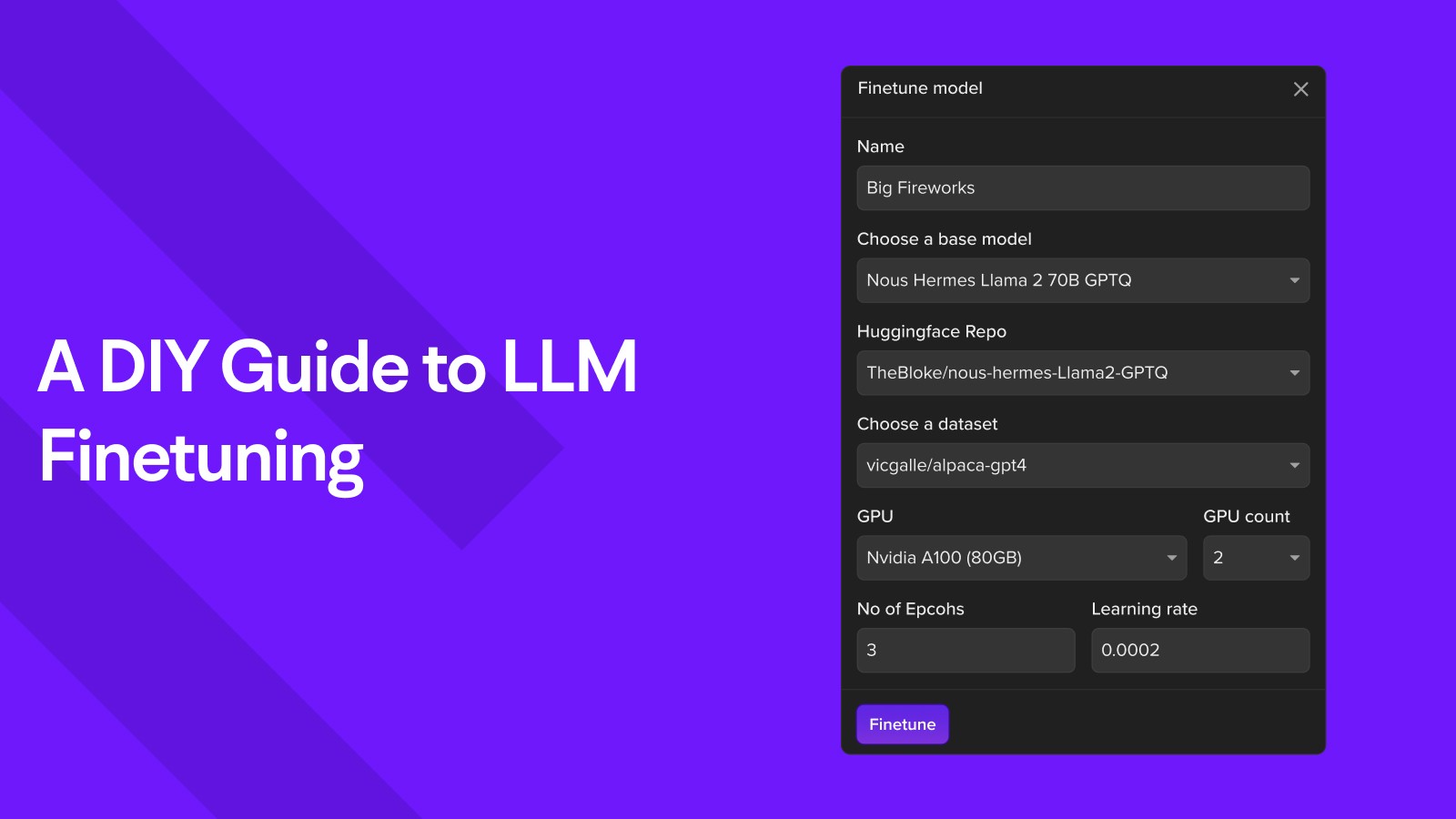
Every guide to Enterprise Large Language Models and Purpose Driven Generative AI boils down to finetuning available models to your dataset and purpose without training these LLMs from scratch. What makes Finetuning LLMs perform differently than their legacy versions? How difficult is finetuning an LLM to your use case in the current market? What will you achieve by finetuning these LLMs?
Today, we look at Finetuning LLMs and try to answer some of these questions to help Finetuning unlock the full potential of LLMs, whether you are an organization or just an enthusiastic developer!
Benefits of Finetuning Your Large Language Model
Before diving into the how, let us consider why you would want to Fine-Tune your large language model and whether it is as deep as all the tutorials online claim. In its simplest form, LLM Fine-tuning is a supervised learning process where you use a custom dataset with labeled data nodes to update the weights of an existing LLM to make it more efficient in a particular task.

Some reasons why Finetuning Large Language Models is beneficial for LLM Pipelines, rather than simply deploying an Open-Source LLM, are as follows:
Transfer Learning: Leveraging Finetuning’s ability to build upon existing pre-trained models to use the existing understanding of syntax, sentence generation, and contextual information regarding the language we use saves computation and time-sensitive inferences on a scaled architecture.
Improved Generalization: Given diverse linguistic patterns, core models tend to capture more generalized features and produce reliable inference results. The overall convergence of the model is also much higher than that of a traditional model, as it wastes less time in linguistic understanding and focuses more on the task at hand.
Domain-Specific Performance: A more conceptual approach to a purpose-driven application dramatically improves the domain-specific performance of the model, as the model is more robust and understands the nuances and vocabulary of the target domain.
Now that we understand the benefits of finetuning let’s look at how to fine-tune Tune Studio using simple steps!
Step-by-Step Guide to Finetuning LLMs with Tune Studio
Perusing various tutorials on Finetuning LLMs, the easiest way to fine-tune an LLM is undoubtedly difficult to come up with, given the plethora of weird hyperparameters, compute restrictions, and the general stigma about the copious amounts of code that go into this. Let us look at how you can fine-tune LLMs on your data on Tune Studio by utilizing the user interface.
Head over to Tune Studio
Head over to Tune Studio > Finetune.
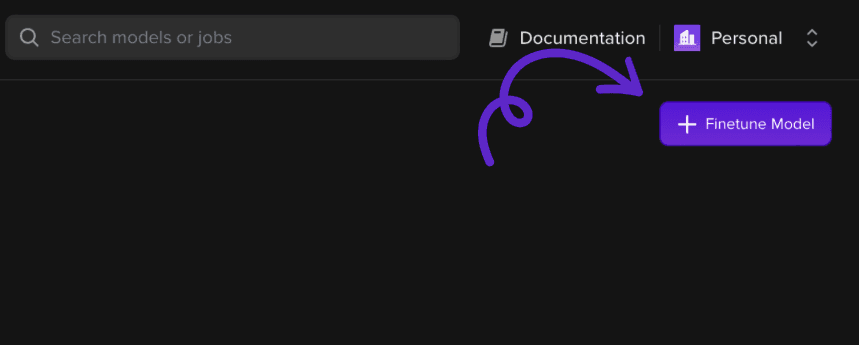
Once on the page, we will select + Finetune Model to add a new finetuning job!
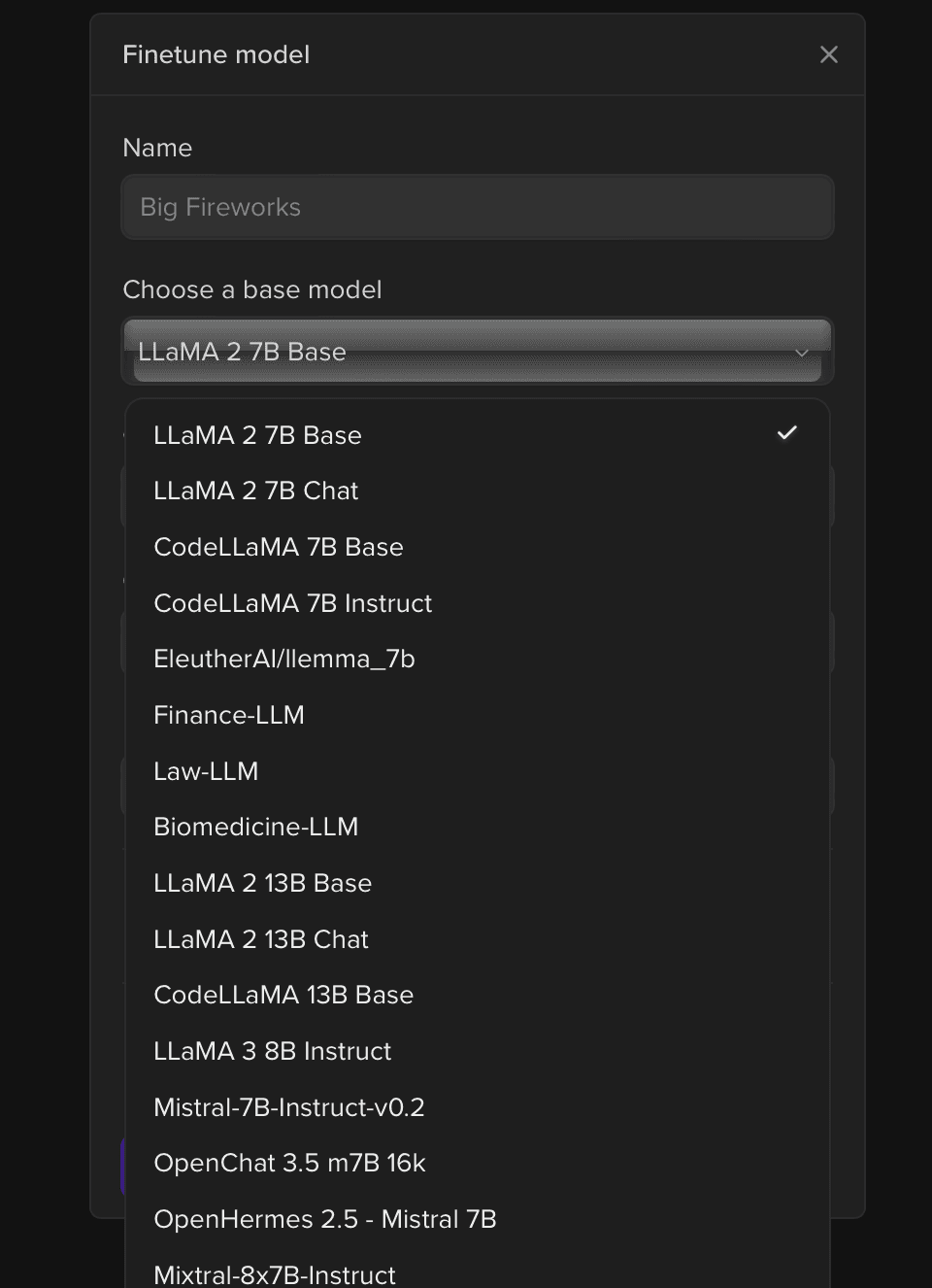
Choose Model, Dataset, and Training Parameters
We will select the base model we want to finetune in the pop-up window.
Once the model is selected, we will choose or upload a dataset.
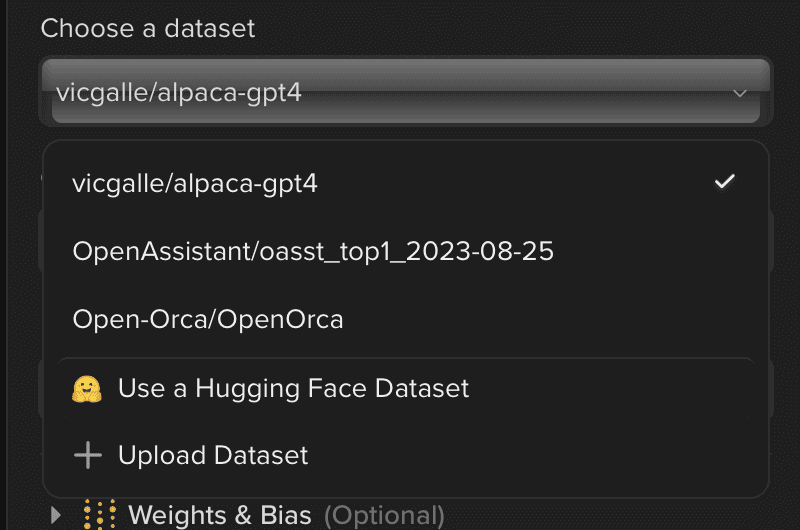
We will then choose the hardware and the hyperparameters for the training.
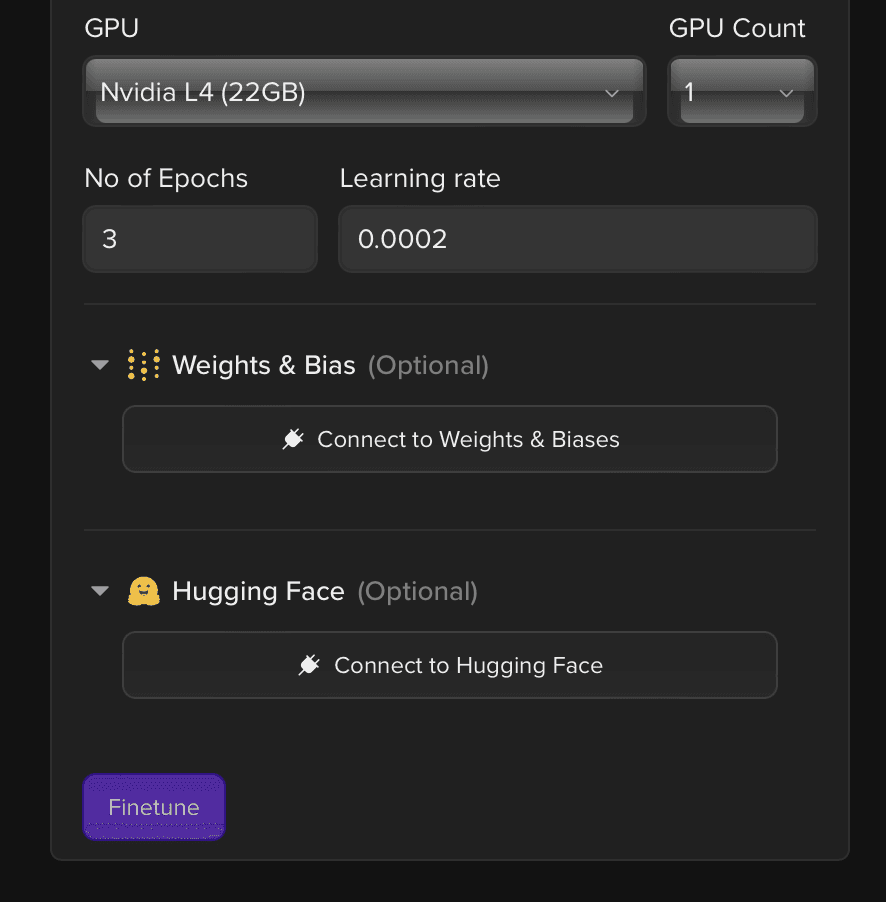
So what are you waiting for? Head over to Tune Studio to try Finetuning Open-Source Large Language Models on your own!
FAQs Related to Finetuning
Before you dive into the beautiful hall of opportunities Finetuning LLMs give you, let us try to answer some more FAQs for the task.
How Long Does Finetuning a Language Model Take?
In an ideal condition where we have close to 12GB+ VRAM, a 7B to 13B parameter model with a dataset of about 10,000 samples can take between 30 minutes and 1 Hour, which can take several hours if the dataset’s sample size is 1 Million+.
How Much Data Is Needed for Finetuning a Language Model?
Let us clarify that fine-tuning a model with an extensive dataset doesn’t guarantee that the new information from the dataset will be embedded in the model itself but instead increases the model’s ability to properly understand the context and linguistic requirements of the task in question. Anything between 10,000 and 5 Million Samples can make the fine-tuning process show better results in the purpose-driven deployment of the models.
What Is a Good Learning Rate for Finetuning?
The learning rate in Finetuning is not necessarily the model’s learning rate but rather the Original Learning Rate of the base model multiplied by the value we set. A higher learning rate will perform better with larger batch sizes, but values between 0.02 and 0.2 in moderate conditions should get you the desired results.

Conclusion
In today’s blog, we saw how everyone can fine-tune open-source large language models on Tune Studio in just a few steps. The blog also highlights the practices that should be followed while fine-tuning LLMs.
Hang in as we discuss deploying your Finetuned Model in a simple web application in the following blogs!
Every guide to Enterprise Large Language Models and Purpose Driven Generative AI boils down to finetuning available models to your dataset and purpose without training these LLMs from scratch. What makes Finetuning LLMs perform differently than their legacy versions? How difficult is finetuning an LLM to your use case in the current market? What will you achieve by finetuning these LLMs?
Today, we look at Finetuning LLMs and try to answer some of these questions to help Finetuning unlock the full potential of LLMs, whether you are an organization or just an enthusiastic developer!
Benefits of Finetuning Your Large Language Model
Before diving into the how, let us consider why you would want to Fine-Tune your large language model and whether it is as deep as all the tutorials online claim. In its simplest form, LLM Fine-tuning is a supervised learning process where you use a custom dataset with labeled data nodes to update the weights of an existing LLM to make it more efficient in a particular task.
Some reasons why Finetuning Large Language Models is beneficial for LLM Pipelines, rather than simply deploying an Open-Source LLM, are as follows:
Transfer Learning: Leveraging Finetuning’s ability to build upon existing pre-trained models to use the existing understanding of syntax, sentence generation, and contextual information regarding the language we use saves computation and time-sensitive inferences on a scaled architecture.
Improved Generalization: Given diverse linguistic patterns, core models tend to capture more generalized features and produce reliable inference results. The overall convergence of the model is also much higher than that of a traditional model, as it wastes less time in linguistic understanding and focuses more on the task at hand.
Domain-Specific Performance: A more conceptual approach to a purpose-driven application dramatically improves the domain-specific performance of the model, as the model is more robust and understands the nuances and vocabulary of the target domain.
Now that we understand the benefits of finetuning let’s look at how to fine-tune Tune Studio using simple steps!
Step-by-Step Guide to Finetuning LLMs with Tune Studio
Perusing various tutorials on Finetuning LLMs, the easiest way to fine-tune an LLM is undoubtedly difficult to come up with, given the plethora of weird hyperparameters, compute restrictions, and the general stigma about the copious amounts of code that go into this. Let us look at how you can fine-tune LLMs on your data on Tune Studio by utilizing the user interface.
Head over to Tune Studio
Head over to Tune Studio > Finetune.
Once on the page, we will select + Finetune Model to add a new finetuning job!
Choose Model, Dataset, and Training Parameters
We will select the base model we want to finetune in the pop-up window.
Once the model is selected, we will choose or upload a dataset.
We will then choose the hardware and the hyperparameters for the training.
So what are you waiting for? Head over to Tune Studio to try Finetuning Open-Source Large Language Models on your own!
FAQs Related to Finetuning
Before you dive into the beautiful hall of opportunities Finetuning LLMs give you, let us try to answer some more FAQs for the task.
How Long Does Finetuning a Language Model Take?
In an ideal condition where we have close to 12GB+ VRAM, a 7B to 13B parameter model with a dataset of about 10,000 samples can take between 30 minutes and 1 Hour, which can take several hours if the dataset’s sample size is 1 Million+.
How Much Data Is Needed for Finetuning a Language Model?
Let us clarify that fine-tuning a model with an extensive dataset doesn’t guarantee that the new information from the dataset will be embedded in the model itself but instead increases the model’s ability to properly understand the context and linguistic requirements of the task in question. Anything between 10,000 and 5 Million Samples can make the fine-tuning process show better results in the purpose-driven deployment of the models.
What Is a Good Learning Rate for Finetuning?
The learning rate in Finetuning is not necessarily the model’s learning rate but rather the Original Learning Rate of the base model multiplied by the value we set. A higher learning rate will perform better with larger batch sizes, but values between 0.02 and 0.2 in moderate conditions should get you the desired results.
Conclusion
In today’s blog, we saw how everyone can fine-tune open-source large language models on Tune Studio in just a few steps. The blog also highlights the practices that should be followed while fine-tuning LLMs.
Hang in as we discuss deploying your Finetuned Model in a simple web application in the following blogs!
Every guide to Enterprise Large Language Models and Purpose Driven Generative AI boils down to finetuning available models to your dataset and purpose without training these LLMs from scratch. What makes Finetuning LLMs perform differently than their legacy versions? How difficult is finetuning an LLM to your use case in the current market? What will you achieve by finetuning these LLMs?
Today, we look at Finetuning LLMs and try to answer some of these questions to help Finetuning unlock the full potential of LLMs, whether you are an organization or just an enthusiastic developer!
Benefits of Finetuning Your Large Language Model
Before diving into the how, let us consider why you would want to Fine-Tune your large language model and whether it is as deep as all the tutorials online claim. In its simplest form, LLM Fine-tuning is a supervised learning process where you use a custom dataset with labeled data nodes to update the weights of an existing LLM to make it more efficient in a particular task.
Some reasons why Finetuning Large Language Models is beneficial for LLM Pipelines, rather than simply deploying an Open-Source LLM, are as follows:
Transfer Learning: Leveraging Finetuning’s ability to build upon existing pre-trained models to use the existing understanding of syntax, sentence generation, and contextual information regarding the language we use saves computation and time-sensitive inferences on a scaled architecture.
Improved Generalization: Given diverse linguistic patterns, core models tend to capture more generalized features and produce reliable inference results. The overall convergence of the model is also much higher than that of a traditional model, as it wastes less time in linguistic understanding and focuses more on the task at hand.
Domain-Specific Performance: A more conceptual approach to a purpose-driven application dramatically improves the domain-specific performance of the model, as the model is more robust and understands the nuances and vocabulary of the target domain.
Now that we understand the benefits of finetuning let’s look at how to fine-tune Tune Studio using simple steps!
Step-by-Step Guide to Finetuning LLMs with Tune Studio
Perusing various tutorials on Finetuning LLMs, the easiest way to fine-tune an LLM is undoubtedly difficult to come up with, given the plethora of weird hyperparameters, compute restrictions, and the general stigma about the copious amounts of code that go into this. Let us look at how you can fine-tune LLMs on your data on Tune Studio by utilizing the user interface.
Head over to Tune Studio
Head over to Tune Studio > Finetune.
Once on the page, we will select + Finetune Model to add a new finetuning job!
Choose Model, Dataset, and Training Parameters
We will select the base model we want to finetune in the pop-up window.
Once the model is selected, we will choose or upload a dataset.
We will then choose the hardware and the hyperparameters for the training.
So what are you waiting for? Head over to Tune Studio to try Finetuning Open-Source Large Language Models on your own!
FAQs Related to Finetuning
Before you dive into the beautiful hall of opportunities Finetuning LLMs give you, let us try to answer some more FAQs for the task.
How Long Does Finetuning a Language Model Take?
In an ideal condition where we have close to 12GB+ VRAM, a 7B to 13B parameter model with a dataset of about 10,000 samples can take between 30 minutes and 1 Hour, which can take several hours if the dataset’s sample size is 1 Million+.
How Much Data Is Needed for Finetuning a Language Model?
Let us clarify that fine-tuning a model with an extensive dataset doesn’t guarantee that the new information from the dataset will be embedded in the model itself but instead increases the model’s ability to properly understand the context and linguistic requirements of the task in question. Anything between 10,000 and 5 Million Samples can make the fine-tuning process show better results in the purpose-driven deployment of the models.
What Is a Good Learning Rate for Finetuning?
The learning rate in Finetuning is not necessarily the model’s learning rate but rather the Original Learning Rate of the base model multiplied by the value we set. A higher learning rate will perform better with larger batch sizes, but values between 0.02 and 0.2 in moderate conditions should get you the desired results.
Conclusion
In today’s blog, we saw how everyone can fine-tune open-source large language models on Tune Studio in just a few steps. The blog also highlights the practices that should be followed while fine-tuning LLMs.
Hang in as we discuss deploying your Finetuned Model in a simple web application in the following blogs!
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.