LLMs
Multi-Modal LLM Implementations in Current Landscape
Jun 7, 2024
3 min read

In the past two years, the AI landscape has undergone a significant transformation for enterprise and open-source development across industries. One of the critical developments has been observed in the sub-landscape of Multi-Modal Large Language Models.
With multiple augmentations to off-the-shelf LLMs, be they closed-source or open-sourced, it has been seen that these MM-LLMs not only preserve the inherent reasoning of LLMs but also empower them to take on various tasks.
Let us break down Multi-Modal LLMs and learn where a new developer can start their journey in such development.
What are Multi-Modal LLMs?
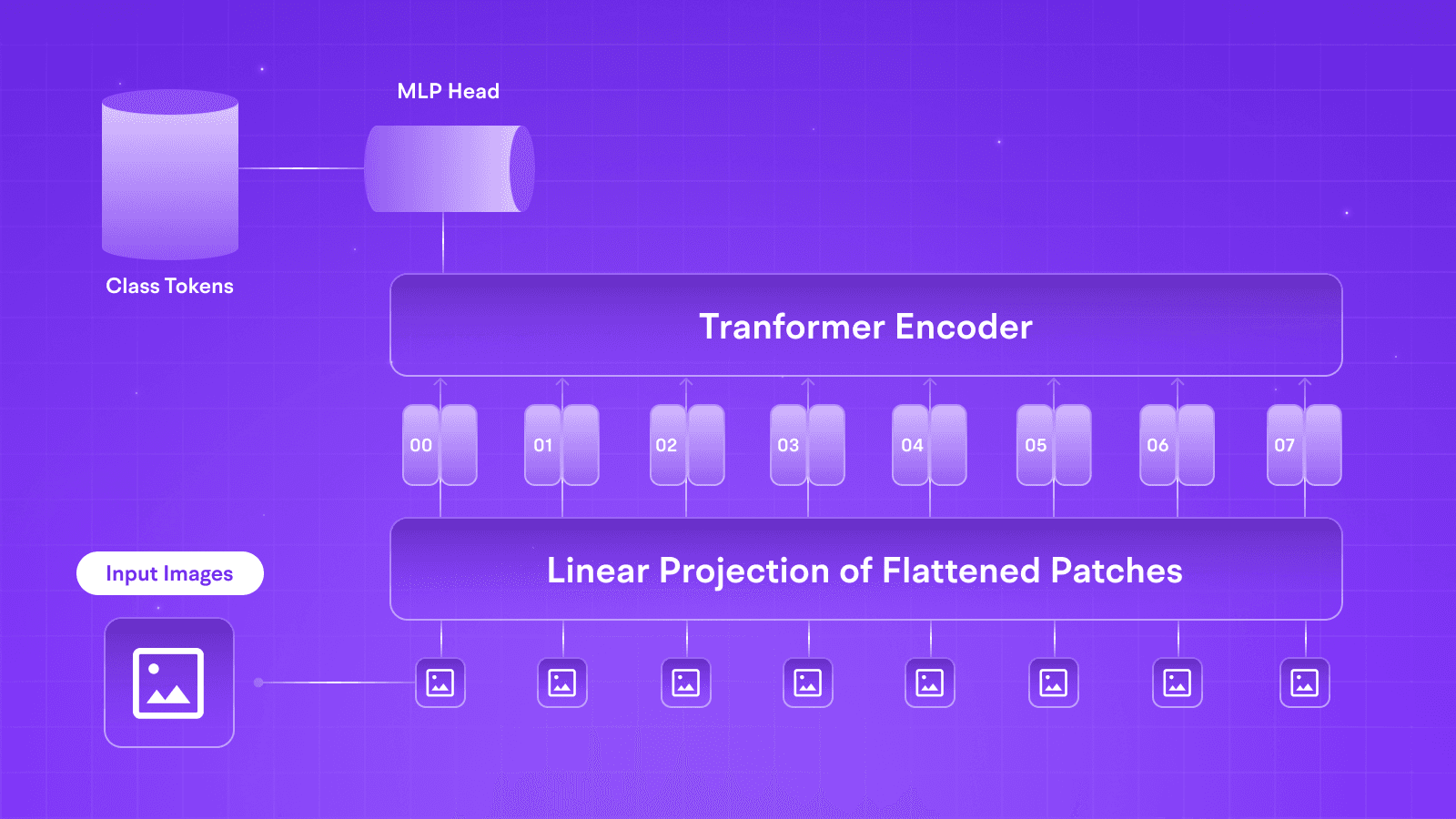
According to the bareback definition of MM-LLMs, these models can range from Input-Output of different modalities to output or input that is multi-modular (meaning they can generate and ingest voice, images, and text). These models have also been termed Vision Language Models.

GPT-4o Multi-Modal Demonstration, Source Wired
With a robust base model, Multi-Modal development aims to conserve a model’s expansive understanding and reasoning, such as Gemini 1.5 or Llama 3, and train it to perform multi-modal tasks, as seen in the newer GPT-4o and Dall E models.
Evolution of Multi-Modal LLMs
One might remember the revolutionary announcement of Dall-E 3, a multi-modal implementation. However, not the very first implementation to coin the word “Multi-Modal,” this model shows the very nature of LLMs and their understanding of semantics and composition.

InternVL MM-LLM In Action, Source Reddit
One good outcome of this launch was the barrage and race among Open-Source Communities and Enterprises to generate Images, Videos, Code, etc, better than GPT, which gave us implementations such as Stable Diffusion, Mid Journey, etc.
These implementations have not only shown the miracle of cost and training mitigation by using legacy models but also a step towards Artificial General Intelligence.
Try Multi-Modal inputs and outputs on Tune Chat today!
Key Features of Multi-Modal LLMs
The key features of Multi-Modal LLMs are similar to fine-tuning a language model on niche data. They leverage techniques like transformers to process and understand different data modalities, including images, audio, and video. These models build upon the fundamental principles of language models but extend their capabilities by incorporating methods such as Text-to-Speech (TTS)and Audio Tokenization to perform surrounding tasks.
Some key redeeming features of MM-LLMs and why they are better than traditional methods are:
Multi-Input Understanding: These models can take input through various data streams, such as audio, image, video, text, document, code, etc., resulting in an enhanced understanding of the prompt and generating contextually accurate output.
Unified Model Architecture: These unified models remove the headache of various deployment and monitoring practices and allow leveraging shared representations across multiple modalities to increase efficiency.
Enhanced User Experience: These models provide a more engaging and interactive experience across modalities, increasing the accessibility of an application multiple-folds and improving the user experience through intuitive ingestion pipelines.
Models to Try
We have consolidated a list of Multi-Modal GenAI Models that you would like to try and further read about.

Conclusion
In conclusion, the advancements in Multi-Modal LLM development have been remarkable, with significant contributions from enterprises and open-source developers. As we move closer to achieving Artificial General Intelligence, these developments play a crucial role.
We invite you to follow our LinkedIn and Twitter to stay updated on upcoming blogs such as Adversarial Attacks in LLMs and Legal Practices in LLM Deployment.
In the past two years, the AI landscape has undergone a significant transformation for enterprise and open-source development across industries. One of the critical developments has been observed in the sub-landscape of Multi-Modal Large Language Models.
With multiple augmentations to off-the-shelf LLMs, be they closed-source or open-sourced, it has been seen that these MM-LLMs not only preserve the inherent reasoning of LLMs but also empower them to take on various tasks.
Let us break down Multi-Modal LLMs and learn where a new developer can start their journey in such development.
What are Multi-Modal LLMs?
According to the bareback definition of MM-LLMs, these models can range from Input-Output of different modalities to output or input that is multi-modular (meaning they can generate and ingest voice, images, and text). These models have also been termed Vision Language Models.
GPT-4o Multi-Modal Demonstration, Source Wired
With a robust base model, Multi-Modal development aims to conserve a model’s expansive understanding and reasoning, such as Gemini 1.5 or Llama 3, and train it to perform multi-modal tasks, as seen in the newer GPT-4o and Dall E models.
Evolution of Multi-Modal LLMs
One might remember the revolutionary announcement of Dall-E 3, a multi-modal implementation. However, not the very first implementation to coin the word “Multi-Modal,” this model shows the very nature of LLMs and their understanding of semantics and composition.
InternVL MM-LLM In Action, Source Reddit
One good outcome of this launch was the barrage and race among Open-Source Communities and Enterprises to generate Images, Videos, Code, etc, better than GPT, which gave us implementations such as Stable Diffusion, Mid Journey, etc.
These implementations have not only shown the miracle of cost and training mitigation by using legacy models but also a step towards Artificial General Intelligence.
Try Multi-Modal inputs and outputs on Tune Chat today!
Key Features of Multi-Modal LLMs
The key features of Multi-Modal LLMs are similar to fine-tuning a language model on niche data. They leverage techniques like transformers to process and understand different data modalities, including images, audio, and video. These models build upon the fundamental principles of language models but extend their capabilities by incorporating methods such as Text-to-Speech (TTS)and Audio Tokenization to perform surrounding tasks.
Some key redeeming features of MM-LLMs and why they are better than traditional methods are:
Multi-Input Understanding: These models can take input through various data streams, such as audio, image, video, text, document, code, etc., resulting in an enhanced understanding of the prompt and generating contextually accurate output.
Unified Model Architecture: These unified models remove the headache of various deployment and monitoring practices and allow leveraging shared representations across multiple modalities to increase efficiency.
Enhanced User Experience: These models provide a more engaging and interactive experience across modalities, increasing the accessibility of an application multiple-folds and improving the user experience through intuitive ingestion pipelines.
Models to Try
We have consolidated a list of Multi-Modal GenAI Models that you would like to try and further read about.
Conclusion
In conclusion, the advancements in Multi-Modal LLM development have been remarkable, with significant contributions from enterprises and open-source developers. As we move closer to achieving Artificial General Intelligence, these developments play a crucial role.
We invite you to follow our LinkedIn and Twitter to stay updated on upcoming blogs such as Adversarial Attacks in LLMs and Legal Practices in LLM Deployment.
In the past two years, the AI landscape has undergone a significant transformation for enterprise and open-source development across industries. One of the critical developments has been observed in the sub-landscape of Multi-Modal Large Language Models.
With multiple augmentations to off-the-shelf LLMs, be they closed-source or open-sourced, it has been seen that these MM-LLMs not only preserve the inherent reasoning of LLMs but also empower them to take on various tasks.
Let us break down Multi-Modal LLMs and learn where a new developer can start their journey in such development.
What are Multi-Modal LLMs?
According to the bareback definition of MM-LLMs, these models can range from Input-Output of different modalities to output or input that is multi-modular (meaning they can generate and ingest voice, images, and text). These models have also been termed Vision Language Models.
GPT-4o Multi-Modal Demonstration, Source Wired
With a robust base model, Multi-Modal development aims to conserve a model’s expansive understanding and reasoning, such as Gemini 1.5 or Llama 3, and train it to perform multi-modal tasks, as seen in the newer GPT-4o and Dall E models.
Evolution of Multi-Modal LLMs
One might remember the revolutionary announcement of Dall-E 3, a multi-modal implementation. However, not the very first implementation to coin the word “Multi-Modal,” this model shows the very nature of LLMs and their understanding of semantics and composition.
InternVL MM-LLM In Action, Source Reddit
One good outcome of this launch was the barrage and race among Open-Source Communities and Enterprises to generate Images, Videos, Code, etc, better than GPT, which gave us implementations such as Stable Diffusion, Mid Journey, etc.
These implementations have not only shown the miracle of cost and training mitigation by using legacy models but also a step towards Artificial General Intelligence.
Try Multi-Modal inputs and outputs on Tune Chat today!
Key Features of Multi-Modal LLMs
The key features of Multi-Modal LLMs are similar to fine-tuning a language model on niche data. They leverage techniques like transformers to process and understand different data modalities, including images, audio, and video. These models build upon the fundamental principles of language models but extend their capabilities by incorporating methods such as Text-to-Speech (TTS)and Audio Tokenization to perform surrounding tasks.
Some key redeeming features of MM-LLMs and why they are better than traditional methods are:
Multi-Input Understanding: These models can take input through various data streams, such as audio, image, video, text, document, code, etc., resulting in an enhanced understanding of the prompt and generating contextually accurate output.
Unified Model Architecture: These unified models remove the headache of various deployment and monitoring practices and allow leveraging shared representations across multiple modalities to increase efficiency.
Enhanced User Experience: These models provide a more engaging and interactive experience across modalities, increasing the accessibility of an application multiple-folds and improving the user experience through intuitive ingestion pipelines.
Models to Try
We have consolidated a list of Multi-Modal GenAI Models that you would like to try and further read about.
Conclusion
In conclusion, the advancements in Multi-Modal LLM development have been remarkable, with significant contributions from enterprises and open-source developers. As we move closer to achieving Artificial General Intelligence, these developments play a crucial role.
We invite you to follow our LinkedIn and Twitter to stay updated on upcoming blogs such as Adversarial Attacks in LLMs and Legal Practices in LLM Deployment.
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.