LLMs
Why are RAGs all the RAGe?
Mar 15, 2024
5 min read

Large Language Models have single-handedly revolutionised the way society and governments worldwide see Artificial Intelligence, but from investors to tech bros, why is everyone talking about RAGs suddenly? We here at Tunehq.ai strive to educate everyone about the current landscape and want to break down what RAGs are and whether your organization invests in some RAGs to clean up your dirty LLM Pipeline.
Let us first look at RAGs and discuss why the partnership between RAGs and LLM Frameworks is so successful and meaningful for pushing and achieving better generative AI.
What is a RAG?
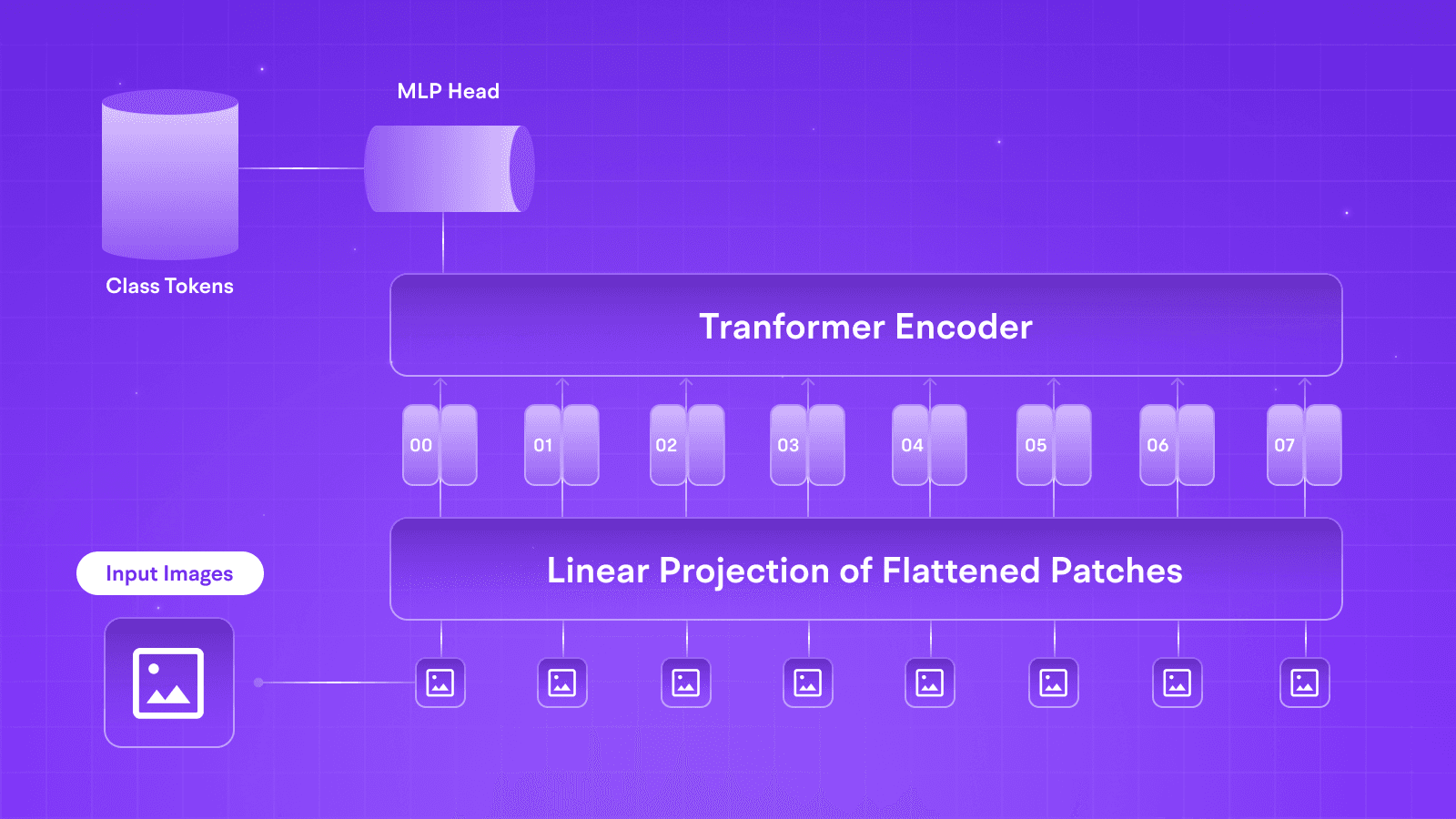
Retrieval-Augmented Generation (RAG) emerges as the convergence of two pivotal elements: Indexing and Retrieval and Generation. These components intricately orchestrate a seamless workflow, elevating the capabilities of language models and pushing the boundaries of contextual understanding.
Indexing: Crafting the Data Symphony

Loading: The initial phase involves introducing data into the RAG ecosystem using DocumentLoaders. This foundational step brings raw data into the system, establishing the groundwork for subsequent processes.
Chunkers: Chunkers dissect large documents into many small manageable segments called chunks. This helps optimize indexing and work with the model's finite context window. This strategic dissection ensures the highest performance.
Vector Store: Refined data segments are processed by embedding models (baby brothers of LLMs) to create embeddings, which are then stored. The collaboration of this Vector Store and Embeddings models forms the foundation for later stages in the RAG pipeline, ensuring efficient storage and retrieval of indexed data.
Retrieval and Generation: The Dynamic Duo in Action

Retrieve: Prompted by the user's query, the Retriever promptly extracts pertinent data segments from storage. This retrieval process sets the stage for subsequent data processing.
Generate: The ChatModel or Large Language Model (LLM) assumes a central role, employing a meticulously crafted prompt—a fusion of the user's query and retrieve data—to generate context-aware responses. This seamless interplay of retrieval and generation defines the core of the RAG framework.
This well-coordinated sequence, from loading raw data to generating insightful answers, encapsulates the essence of RAG. The framework integrates offline processes such as data loading, splitting, and storing with real-time user interactions, delivering a dynamic and contextually rich language processing experience.
The RAG framework, with its distinctive components operating in harmonious synchronization, signifies a paradigm shift in the landscape of natural language processing. It heralds a new era of sophisticated and responsive AI applications, redefining the boundaries of contextual understanding and responsiveness.
The Rise of RAGs with LangChain!
About a year ago, when developers were faced with a black box of code in the form of ChatGPT, several people started experimenting with the power and challenges of context for a truly smart chatbot. Earlier thought to be so powerful because of RLHF, RAGs soon were realized to be the reason for such powerful context detection and conversations. (Head over to our article on RLHF to understand what Reinforcement Learning from Human Feedback can achieve in LLMs).
Retrieval-Augmented Generative models (RAGs) work seamlessly with frameworks like LangChain and other Large Language Models (LLMs), enhancing their functionality in several key ways:
Contextual Enrichment: LangChain and similar LLM frameworks often focus on generating coherent and contextually relevant language. When integrated with RAGs, these frameworks benefit from the retrieval component, which allows them to access and incorporate information from external sources.
Dynamic Information Retrieval: LangChain and other LLM frameworks typically rely on pre-trained models to generate text. By incorporating RAGs, these frameworks gain the ability to dynamically retrieve and update information from external databases or knowledge bases in real time.
Efficient Handling of Vast Knowledge Bases: RAGs are particularly effective in handling vast knowledge bases, and this capability complements LLM frameworks like LangChain. The retrieval mechanism allows the model to efficiently navigate and extract relevant information from extensive datasets, providing a comprehensive understanding of the context and enabling more accurate and detailed responses.
Tailored Responses for Specific Domains: LangChain and other LLM frameworks may be designed for specific domains or industries. Integrating RAGs allows these models to tailor their responses based on the specific needs and nuances of the domain.
Multimodal Integration: LangChain and other LLM frameworks may primarily focus on text-based generation. When coupled with RAGs, which can handle multimodal data retrieval, the combined model can integrate information from diverse sources, including images and videos. (Head over to Tunehq.ai to try our own plethora of multimodal applications)
RAGs with frameworks like LangChain enhance language models’ overall performance and capabilities. It introduces dynamic information retrieval, contextual enrichment, and domain-specific tailoring, making them more adaptive and effective across various applications.

Over the years, one of our most proud contributions to Open-Source has been ChainFury, our own take on the famous framework. ChainFury is a robust platform that harnesses the full potential of LLMs (large language models) and allows you to easily chain together prompts, utilities, and agents to create complex chat applications. Adding to the visual appearance of LangFlow, ChainFury is focused solely on the CRUDL of the chat, chatbots, and other resources, industry-standard authentication, and JS-embeddable chatbox, making it a far superior implementation of chains.
Revolutionizing Larger and Complex Models
Collaboration with domain experts is expected to become more prevalent to enhance the capabilities of RAGs further. Integrating subject matter expertise into the development process can lead to more accurate and contextually relevant models, particularly in specialized fields where domain-specific knowledge is crucial.
As we delve deeper into the potential of Retrieval-Augmented Generative models, it's evident that the synergy between retrieval and generation will continue to redefine the possibilities of large language models. From enhanced understanding to more accurate and context-aware outputs, RAGs represent a pivotal step towards unlocking the full potential of artificial intelligence.
Conclusion
In conclusion, the surge in discussions surrounding Retrieval-Augmented Generative Models (RAGs) is not merely a passing trend but a reflection of a groundbreaking advancement in the realm of artificial intelligence. While Large Language Models (LLMs) have already transformed the landscape, RAGs, with their fusion of indexing, retrieval, and generation components, stand out as the catalysts for a new era of sophisticated and responsive AI applications.
RAGs are like the infinite memory of the AI.
At Tunehq.ai, we advocate for understanding and embracing this transformative technology. Looking ahead, the collaborative efforts with domain experts promise to refine RAGs even further, ensuring that they keep pace with evolving industries and lead to more accurate and contextually relevant models.
Large Language Models have single-handedly revolutionised the way society and governments worldwide see Artificial Intelligence, but from investors to tech bros, why is everyone talking about RAGs suddenly? We here at Tunehq.ai strive to educate everyone about the current landscape and want to break down what RAGs are and whether your organization invests in some RAGs to clean up your dirty LLM Pipeline.
Let us first look at RAGs and discuss why the partnership between RAGs and LLM Frameworks is so successful and meaningful for pushing and achieving better generative AI.
What is a RAG?
Retrieval-Augmented Generation (RAG) emerges as the convergence of two pivotal elements: Indexing and Retrieval and Generation. These components intricately orchestrate a seamless workflow, elevating the capabilities of language models and pushing the boundaries of contextual understanding.
Indexing: Crafting the Data Symphony
Loading: The initial phase involves introducing data into the RAG ecosystem using DocumentLoaders. This foundational step brings raw data into the system, establishing the groundwork for subsequent processes.
Chunkers: Chunkers dissect large documents into many small manageable segments called chunks. This helps optimize indexing and work with the model's finite context window. This strategic dissection ensures the highest performance.
Vector Store: Refined data segments are processed by embedding models (baby brothers of LLMs) to create embeddings, which are then stored. The collaboration of this Vector Store and Embeddings models forms the foundation for later stages in the RAG pipeline, ensuring efficient storage and retrieval of indexed data.
Retrieval and Generation: The Dynamic Duo in Action
Retrieve: Prompted by the user's query, the Retriever promptly extracts pertinent data segments from storage. This retrieval process sets the stage for subsequent data processing.
Generate: The ChatModel or Large Language Model (LLM) assumes a central role, employing a meticulously crafted prompt—a fusion of the user's query and retrieve data—to generate context-aware responses. This seamless interplay of retrieval and generation defines the core of the RAG framework.
This well-coordinated sequence, from loading raw data to generating insightful answers, encapsulates the essence of RAG. The framework integrates offline processes such as data loading, splitting, and storing with real-time user interactions, delivering a dynamic and contextually rich language processing experience.
The RAG framework, with its distinctive components operating in harmonious synchronization, signifies a paradigm shift in the landscape of natural language processing. It heralds a new era of sophisticated and responsive AI applications, redefining the boundaries of contextual understanding and responsiveness.
The Rise of RAGs with LangChain!
About a year ago, when developers were faced with a black box of code in the form of ChatGPT, several people started experimenting with the power and challenges of context for a truly smart chatbot. Earlier thought to be so powerful because of RLHF, RAGs soon were realized to be the reason for such powerful context detection and conversations. (Head over to our article on RLHF to understand what Reinforcement Learning from Human Feedback can achieve in LLMs).
Retrieval-Augmented Generative models (RAGs) work seamlessly with frameworks like LangChain and other Large Language Models (LLMs), enhancing their functionality in several key ways:
Contextual Enrichment: LangChain and similar LLM frameworks often focus on generating coherent and contextually relevant language. When integrated with RAGs, these frameworks benefit from the retrieval component, which allows them to access and incorporate information from external sources.
Dynamic Information Retrieval: LangChain and other LLM frameworks typically rely on pre-trained models to generate text. By incorporating RAGs, these frameworks gain the ability to dynamically retrieve and update information from external databases or knowledge bases in real time.
Efficient Handling of Vast Knowledge Bases: RAGs are particularly effective in handling vast knowledge bases, and this capability complements LLM frameworks like LangChain. The retrieval mechanism allows the model to efficiently navigate and extract relevant information from extensive datasets, providing a comprehensive understanding of the context and enabling more accurate and detailed responses.
Tailored Responses for Specific Domains: LangChain and other LLM frameworks may be designed for specific domains or industries. Integrating RAGs allows these models to tailor their responses based on the specific needs and nuances of the domain.
Multimodal Integration: LangChain and other LLM frameworks may primarily focus on text-based generation. When coupled with RAGs, which can handle multimodal data retrieval, the combined model can integrate information from diverse sources, including images and videos. (Head over to Tunehq.ai to try our own plethora of multimodal applications)
RAGs with frameworks like LangChain enhance language models’ overall performance and capabilities. It introduces dynamic information retrieval, contextual enrichment, and domain-specific tailoring, making them more adaptive and effective across various applications.
Over the years, one of our most proud contributions to Open-Source has been ChainFury, our own take on the famous framework. ChainFury is a robust platform that harnesses the full potential of LLMs (large language models) and allows you to easily chain together prompts, utilities, and agents to create complex chat applications. Adding to the visual appearance of LangFlow, ChainFury is focused solely on the CRUDL of the chat, chatbots, and other resources, industry-standard authentication, and JS-embeddable chatbox, making it a far superior implementation of chains.
Revolutionizing Larger and Complex Models
Collaboration with domain experts is expected to become more prevalent to enhance the capabilities of RAGs further. Integrating subject matter expertise into the development process can lead to more accurate and contextually relevant models, particularly in specialized fields where domain-specific knowledge is crucial.
As we delve deeper into the potential of Retrieval-Augmented Generative models, it's evident that the synergy between retrieval and generation will continue to redefine the possibilities of large language models. From enhanced understanding to more accurate and context-aware outputs, RAGs represent a pivotal step towards unlocking the full potential of artificial intelligence.
Conclusion
In conclusion, the surge in discussions surrounding Retrieval-Augmented Generative Models (RAGs) is not merely a passing trend but a reflection of a groundbreaking advancement in the realm of artificial intelligence. While Large Language Models (LLMs) have already transformed the landscape, RAGs, with their fusion of indexing, retrieval, and generation components, stand out as the catalysts for a new era of sophisticated and responsive AI applications.
RAGs are like the infinite memory of the AI.
At Tunehq.ai, we advocate for understanding and embracing this transformative technology. Looking ahead, the collaborative efforts with domain experts promise to refine RAGs even further, ensuring that they keep pace with evolving industries and lead to more accurate and contextually relevant models.
Large Language Models have single-handedly revolutionised the way society and governments worldwide see Artificial Intelligence, but from investors to tech bros, why is everyone talking about RAGs suddenly? We here at Tunehq.ai strive to educate everyone about the current landscape and want to break down what RAGs are and whether your organization invests in some RAGs to clean up your dirty LLM Pipeline.
Let us first look at RAGs and discuss why the partnership between RAGs and LLM Frameworks is so successful and meaningful for pushing and achieving better generative AI.
What is a RAG?
Retrieval-Augmented Generation (RAG) emerges as the convergence of two pivotal elements: Indexing and Retrieval and Generation. These components intricately orchestrate a seamless workflow, elevating the capabilities of language models and pushing the boundaries of contextual understanding.
Indexing: Crafting the Data Symphony
Loading: The initial phase involves introducing data into the RAG ecosystem using DocumentLoaders. This foundational step brings raw data into the system, establishing the groundwork for subsequent processes.
Chunkers: Chunkers dissect large documents into many small manageable segments called chunks. This helps optimize indexing and work with the model's finite context window. This strategic dissection ensures the highest performance.
Vector Store: Refined data segments are processed by embedding models (baby brothers of LLMs) to create embeddings, which are then stored. The collaboration of this Vector Store and Embeddings models forms the foundation for later stages in the RAG pipeline, ensuring efficient storage and retrieval of indexed data.
Retrieval and Generation: The Dynamic Duo in Action
Retrieve: Prompted by the user's query, the Retriever promptly extracts pertinent data segments from storage. This retrieval process sets the stage for subsequent data processing.
Generate: The ChatModel or Large Language Model (LLM) assumes a central role, employing a meticulously crafted prompt—a fusion of the user's query and retrieve data—to generate context-aware responses. This seamless interplay of retrieval and generation defines the core of the RAG framework.
This well-coordinated sequence, from loading raw data to generating insightful answers, encapsulates the essence of RAG. The framework integrates offline processes such as data loading, splitting, and storing with real-time user interactions, delivering a dynamic and contextually rich language processing experience.
The RAG framework, with its distinctive components operating in harmonious synchronization, signifies a paradigm shift in the landscape of natural language processing. It heralds a new era of sophisticated and responsive AI applications, redefining the boundaries of contextual understanding and responsiveness.
The Rise of RAGs with LangChain!
About a year ago, when developers were faced with a black box of code in the form of ChatGPT, several people started experimenting with the power and challenges of context for a truly smart chatbot. Earlier thought to be so powerful because of RLHF, RAGs soon were realized to be the reason for such powerful context detection and conversations. (Head over to our article on RLHF to understand what Reinforcement Learning from Human Feedback can achieve in LLMs).
Retrieval-Augmented Generative models (RAGs) work seamlessly with frameworks like LangChain and other Large Language Models (LLMs), enhancing their functionality in several key ways:
Contextual Enrichment: LangChain and similar LLM frameworks often focus on generating coherent and contextually relevant language. When integrated with RAGs, these frameworks benefit from the retrieval component, which allows them to access and incorporate information from external sources.
Dynamic Information Retrieval: LangChain and other LLM frameworks typically rely on pre-trained models to generate text. By incorporating RAGs, these frameworks gain the ability to dynamically retrieve and update information from external databases or knowledge bases in real time.
Efficient Handling of Vast Knowledge Bases: RAGs are particularly effective in handling vast knowledge bases, and this capability complements LLM frameworks like LangChain. The retrieval mechanism allows the model to efficiently navigate and extract relevant information from extensive datasets, providing a comprehensive understanding of the context and enabling more accurate and detailed responses.
Tailored Responses for Specific Domains: LangChain and other LLM frameworks may be designed for specific domains or industries. Integrating RAGs allows these models to tailor their responses based on the specific needs and nuances of the domain.
Multimodal Integration: LangChain and other LLM frameworks may primarily focus on text-based generation. When coupled with RAGs, which can handle multimodal data retrieval, the combined model can integrate information from diverse sources, including images and videos. (Head over to Tunehq.ai to try our own plethora of multimodal applications)
RAGs with frameworks like LangChain enhance language models’ overall performance and capabilities. It introduces dynamic information retrieval, contextual enrichment, and domain-specific tailoring, making them more adaptive and effective across various applications.
Over the years, one of our most proud contributions to Open-Source has been ChainFury, our own take on the famous framework. ChainFury is a robust platform that harnesses the full potential of LLMs (large language models) and allows you to easily chain together prompts, utilities, and agents to create complex chat applications. Adding to the visual appearance of LangFlow, ChainFury is focused solely on the CRUDL of the chat, chatbots, and other resources, industry-standard authentication, and JS-embeddable chatbox, making it a far superior implementation of chains.
Revolutionizing Larger and Complex Models
Collaboration with domain experts is expected to become more prevalent to enhance the capabilities of RAGs further. Integrating subject matter expertise into the development process can lead to more accurate and contextually relevant models, particularly in specialized fields where domain-specific knowledge is crucial.
As we delve deeper into the potential of Retrieval-Augmented Generative models, it's evident that the synergy between retrieval and generation will continue to redefine the possibilities of large language models. From enhanced understanding to more accurate and context-aware outputs, RAGs represent a pivotal step towards unlocking the full potential of artificial intelligence.
Conclusion
In conclusion, the surge in discussions surrounding Retrieval-Augmented Generative Models (RAGs) is not merely a passing trend but a reflection of a groundbreaking advancement in the realm of artificial intelligence. While Large Language Models (LLMs) have already transformed the landscape, RAGs, with their fusion of indexing, retrieval, and generation components, stand out as the catalysts for a new era of sophisticated and responsive AI applications.
RAGs are like the infinite memory of the AI.
At Tunehq.ai, we advocate for understanding and embracing this transformative technology. Looking ahead, the collaborative efforts with domain experts promise to refine RAGs even further, ensuring that they keep pace with evolving industries and lead to more accurate and contextually relevant models.
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.