LLMs
Llama 3.2 VL Available on Tune Studio
Sep 27, 2024
2 min read

We are excited to share that Meta has just unveiled Llama 3.2. Both Tune Studio and Tune Chat now support the multimodal inference model. So, let's first look at this new model from Meta and how you can use it on Tune.
What’s New in Llama?
Released almost two months after the release of their extra large language model Llama 3.1 405B, this new release from Meta seems long due. With the latest winds in the LLM sphere ringing with the launches of one multi-modal LLM to another, Llama 3.2 joins the party late after Mistral AI’s Pixtral 12B and Qwen 2 VLs. With the model being the first in the Llama series to support visual and textual inputs, we get to analyse images alongside text.

The model also supports voice interaction, which enables users to converse with the AI using spoken commands. Funnily enough, this coincides with ChatGPT’s launch of the long-promised Voice integration, which arrives almost four months after the feature announcement. Let us now look at some of the model's key features and why you should care about the model.
What Makes Llama 3.2 Special?
The new Meta iteration has four variations: 1B, 3B, 11B, and 90B. Meta’s commitment to catering to different use cases has led to diversifying model parameters. The smaller models make smartphone integrations easier. While the models are smaller, they have been trained upon 9 trillion tokens, which come from the distillation of the larger models. This makes them sure to fulfil any query you throw at them.

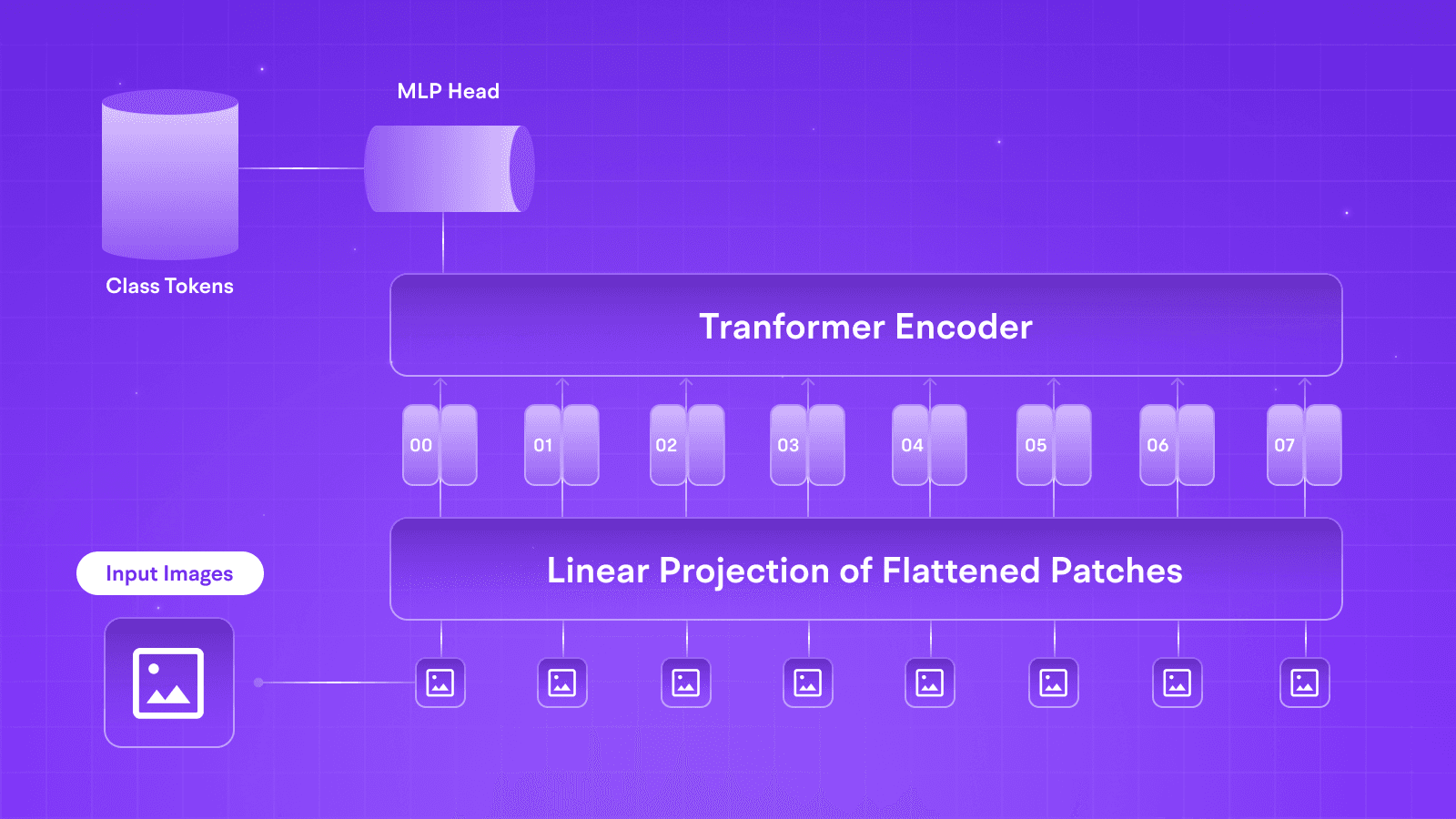
The larger models, however, come with long-awaited support for vision queries. The architecture's vision encoder uses a CLIP-type MLP with GeLU activation similar to the ones used in early GPT models but diverges from Llama 3’s MLP, which previously employed SwiGLU. These models have been further trained upon 6 billion image-text pairs, enabling them to learn nuanced relationships among data points.

Initial evaluations for the models show promising results, with the 1B model achieving 49.3 on the MMLU benchmark and the 3B model scoring 63.4. The multimodal VLMs also perform well, earning scores of 50.7 for the 11B model and 60.3 for the 90B model on the MMMU Benchmark, compared to Claude Haiku’s 50.2 and GPT4o Mini’s 59.4.
How to Use Llama 3.2 on Tune Studio
Users can quickly start interacting with the model on Tune Studio for free. There are three ways of interacting with the model.
Tune Studio
Llama 3.2 90B Vision can be accessed on Tune Studio through Models with the model-ID meta/llama-3.2-90b-vision. Henceforth, the model can be opened in Playground to tinker with.

API Calls
The model can be integrated into applications using the Tune API Commands (to learn more about image inferences with Tune API, check out Vision Completion on Tune Docs)
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "https://chat.tune.app/icon-512.png" } } ] } ], "model": "meta/llama-3.2-90b-vision", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Tune Chat
Finally, lightweight users can directly interact with the model on Tune Chat for smooth inferences and interaction to understand the weird circuit diagram your professor discussed today!

Conclusion
The release of Llama 3.2 VL models is a significant stepping stone for AGI. The model’s ability to perform instruction-conditioned queries on visual data holds the ability to become every enthusiast or organisation’s ace in the arsenal. So go ahead and check out Llama 3.2 on Tune Studio and tag us on socials with your creations.
Further Reading
We are excited to share that Meta has just unveiled Llama 3.2. Both Tune Studio and Tune Chat now support the multimodal inference model. So, let's first look at this new model from Meta and how you can use it on Tune.
What’s New in Llama?
Released almost two months after the release of their extra large language model Llama 3.1 405B, this new release from Meta seems long due. With the latest winds in the LLM sphere ringing with the launches of one multi-modal LLM to another, Llama 3.2 joins the party late after Mistral AI’s Pixtral 12B and Qwen 2 VLs. With the model being the first in the Llama series to support visual and textual inputs, we get to analyse images alongside text.
The model also supports voice interaction, which enables users to converse with the AI using spoken commands. Funnily enough, this coincides with ChatGPT’s launch of the long-promised Voice integration, which arrives almost four months after the feature announcement. Let us now look at some of the model's key features and why you should care about the model.
What Makes Llama 3.2 Special?
The new Meta iteration has four variations: 1B, 3B, 11B, and 90B. Meta’s commitment to catering to different use cases has led to diversifying model parameters. The smaller models make smartphone integrations easier. While the models are smaller, they have been trained upon 9 trillion tokens, which come from the distillation of the larger models. This makes them sure to fulfil any query you throw at them.
The larger models, however, come with long-awaited support for vision queries. The architecture's vision encoder uses a CLIP-type MLP with GeLU activation similar to the ones used in early GPT models but diverges from Llama 3’s MLP, which previously employed SwiGLU. These models have been further trained upon 6 billion image-text pairs, enabling them to learn nuanced relationships among data points.
Initial evaluations for the models show promising results, with the 1B model achieving 49.3 on the MMLU benchmark and the 3B model scoring 63.4. The multimodal VLMs also perform well, earning scores of 50.7 for the 11B model and 60.3 for the 90B model on the MMMU Benchmark, compared to Claude Haiku’s 50.2 and GPT4o Mini’s 59.4.
How to Use Llama 3.2 on Tune Studio
Users can quickly start interacting with the model on Tune Studio for free. There are three ways of interacting with the model.
Tune Studio
Llama 3.2 90B Vision can be accessed on Tune Studio through Models with the model-ID meta/llama-3.2-90b-vision. Henceforth, the model can be opened in Playground to tinker with.
API Calls
The model can be integrated into applications using the Tune API Commands (to learn more about image inferences with Tune API, check out Vision Completion on Tune Docs)
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "https://chat.tune.app/icon-512.png" } } ] } ], "model": "meta/llama-3.2-90b-vision", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Tune Chat
Finally, lightweight users can directly interact with the model on Tune Chat for smooth inferences and interaction to understand the weird circuit diagram your professor discussed today!
Conclusion
The release of Llama 3.2 VL models is a significant stepping stone for AGI. The model’s ability to perform instruction-conditioned queries on visual data holds the ability to become every enthusiast or organisation’s ace in the arsenal. So go ahead and check out Llama 3.2 on Tune Studio and tag us on socials with your creations.
Further Reading
We are excited to share that Meta has just unveiled Llama 3.2. Both Tune Studio and Tune Chat now support the multimodal inference model. So, let's first look at this new model from Meta and how you can use it on Tune.
What’s New in Llama?
Released almost two months after the release of their extra large language model Llama 3.1 405B, this new release from Meta seems long due. With the latest winds in the LLM sphere ringing with the launches of one multi-modal LLM to another, Llama 3.2 joins the party late after Mistral AI’s Pixtral 12B and Qwen 2 VLs. With the model being the first in the Llama series to support visual and textual inputs, we get to analyse images alongside text.
The model also supports voice interaction, which enables users to converse with the AI using spoken commands. Funnily enough, this coincides with ChatGPT’s launch of the long-promised Voice integration, which arrives almost four months after the feature announcement. Let us now look at some of the model's key features and why you should care about the model.
What Makes Llama 3.2 Special?
The new Meta iteration has four variations: 1B, 3B, 11B, and 90B. Meta’s commitment to catering to different use cases has led to diversifying model parameters. The smaller models make smartphone integrations easier. While the models are smaller, they have been trained upon 9 trillion tokens, which come from the distillation of the larger models. This makes them sure to fulfil any query you throw at them.
The larger models, however, come with long-awaited support for vision queries. The architecture's vision encoder uses a CLIP-type MLP with GeLU activation similar to the ones used in early GPT models but diverges from Llama 3’s MLP, which previously employed SwiGLU. These models have been further trained upon 6 billion image-text pairs, enabling them to learn nuanced relationships among data points.
Initial evaluations for the models show promising results, with the 1B model achieving 49.3 on the MMLU benchmark and the 3B model scoring 63.4. The multimodal VLMs also perform well, earning scores of 50.7 for the 11B model and 60.3 for the 90B model on the MMMU Benchmark, compared to Claude Haiku’s 50.2 and GPT4o Mini’s 59.4.
How to Use Llama 3.2 on Tune Studio
Users can quickly start interacting with the model on Tune Studio for free. There are three ways of interacting with the model.
Tune Studio
Llama 3.2 90B Vision can be accessed on Tune Studio through Models with the model-ID meta/llama-3.2-90b-vision. Henceforth, the model can be opened in Playground to tinker with.
API Calls
The model can be integrated into applications using the Tune API Commands (to learn more about image inferences with Tune API, check out Vision Completion on Tune Docs)
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "https://chat.tune.app/icon-512.png" } } ] } ], "model": "meta/llama-3.2-90b-vision", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Tune Chat
Finally, lightweight users can directly interact with the model on Tune Chat for smooth inferences and interaction to understand the weird circuit diagram your professor discussed today!
Conclusion
The release of Llama 3.2 VL models is a significant stepping stone for AGI. The model’s ability to perform instruction-conditioned queries on visual data holds the ability to become every enthusiast or organisation’s ace in the arsenal. So go ahead and check out Llama 3.2 on Tune Studio and tag us on socials with your creations.
Further Reading
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.