LLMs
VLMs: Multi-Modal Integrations on Tune Studio
Oct 14, 2024
5 min read

Are you tired of conversing with your model through text and spending countless hours trying to make it understand the weird circuit diagram you are trying to calculate the capacitance for? Would your RAG pipeline tag images for relevant pulls and retrieval? Vision Language Models might just be the touch of Multi-Modal magic you need.
With many Vision Language Models ranging from closed-source to open-source, be it GPT, Claude or Gemini, Tune API lets you easily integrate these models into your pipeline using simple curl commands. In this blog, we shall check out what vision language models are and how you can use them for various applications easily.
What are Vision Language Models?
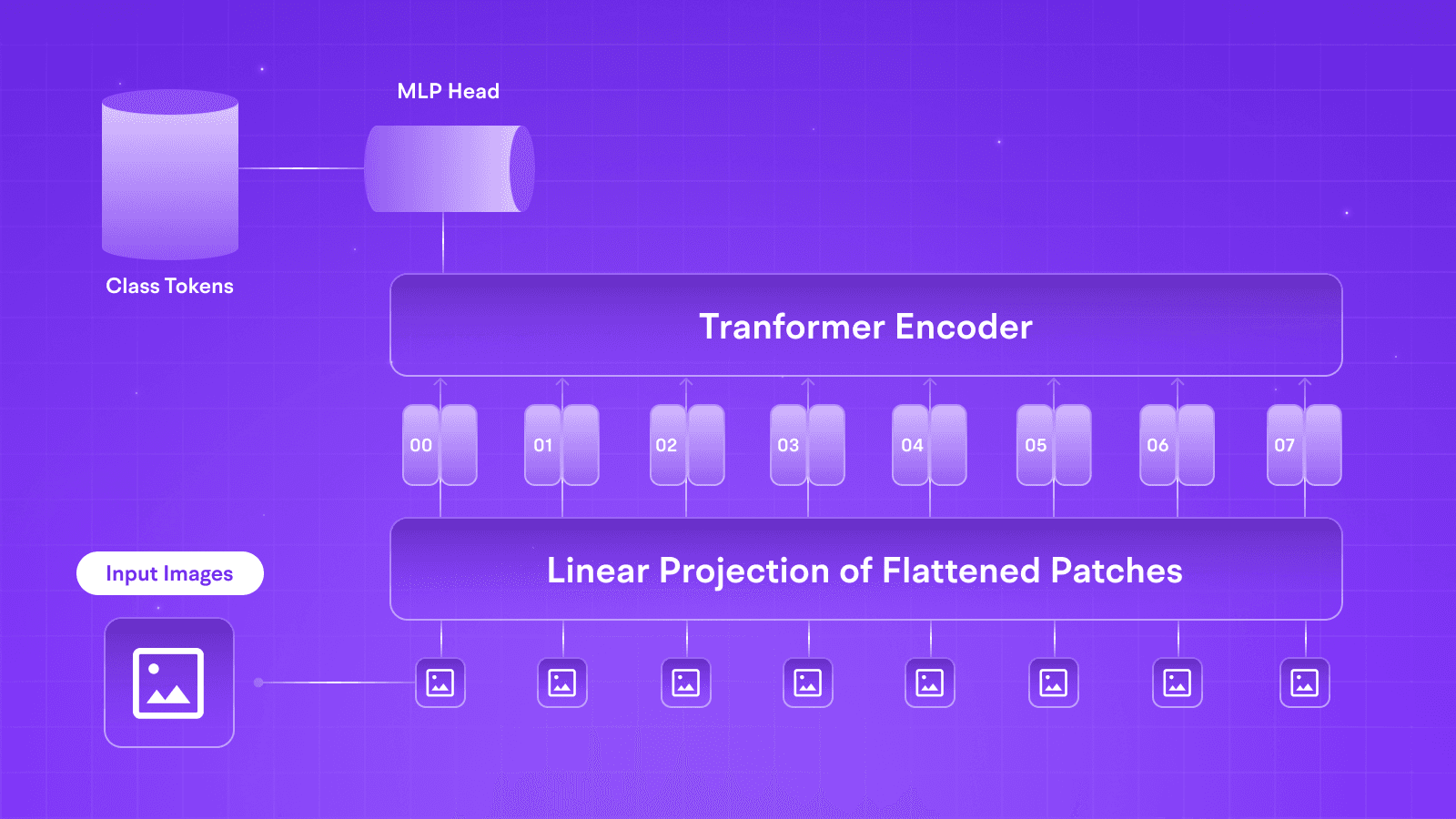
Vision Language models are a class of GenAI models that act as a step towards achieving multi-modal prowess in such systems by allowing them to interact with images. These models can also harness diffusion techniques to generate images according to their understanding of prompts. Unlike traditional CNN architectures or initial vision transformers, such models let a context-rich large language model seamlessly communicate with images by mapping relevant textual embeddings to corresponding image embeddings.
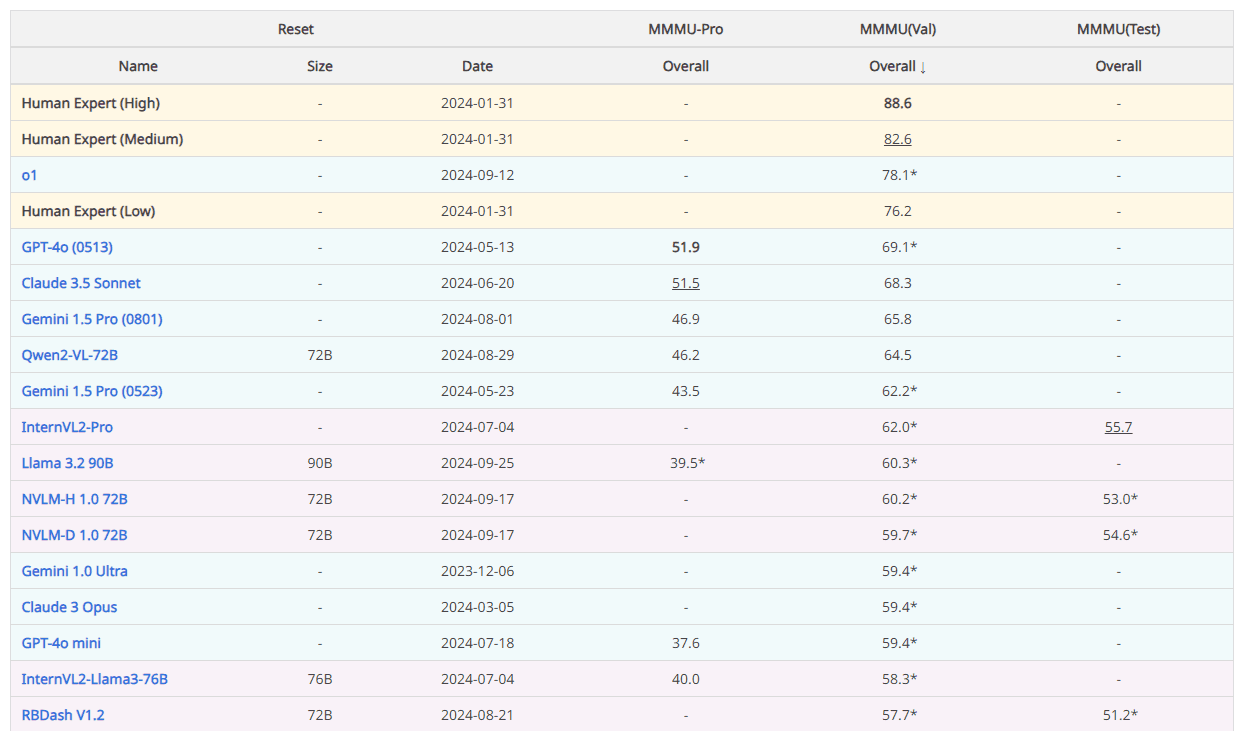
Some exceptional tasks where these models shine the most are Visual Question Answering, Image Captioning, Multi-Modal Search, and Content Moderation, with visual QA serving as a significant benchmark for their performance and usability. Unlike traditional CNN-based computer vision techniques, Transformer-based models lack a dense understanding of the relationship between different pixels but instead excel in looking at the entire picture at once through patches and making a prediction that sufficiently answers the textual query.
VLM Integrations using Tune API
As the industry has evolved, so have we; Tune Studio and Tune Chat have been actively helping researchers and professionals access these models. Including an array of closed-source and open-source VLMs, users can also go beyond a simple bot chat and integrate these VLMs into their applications through API calls.
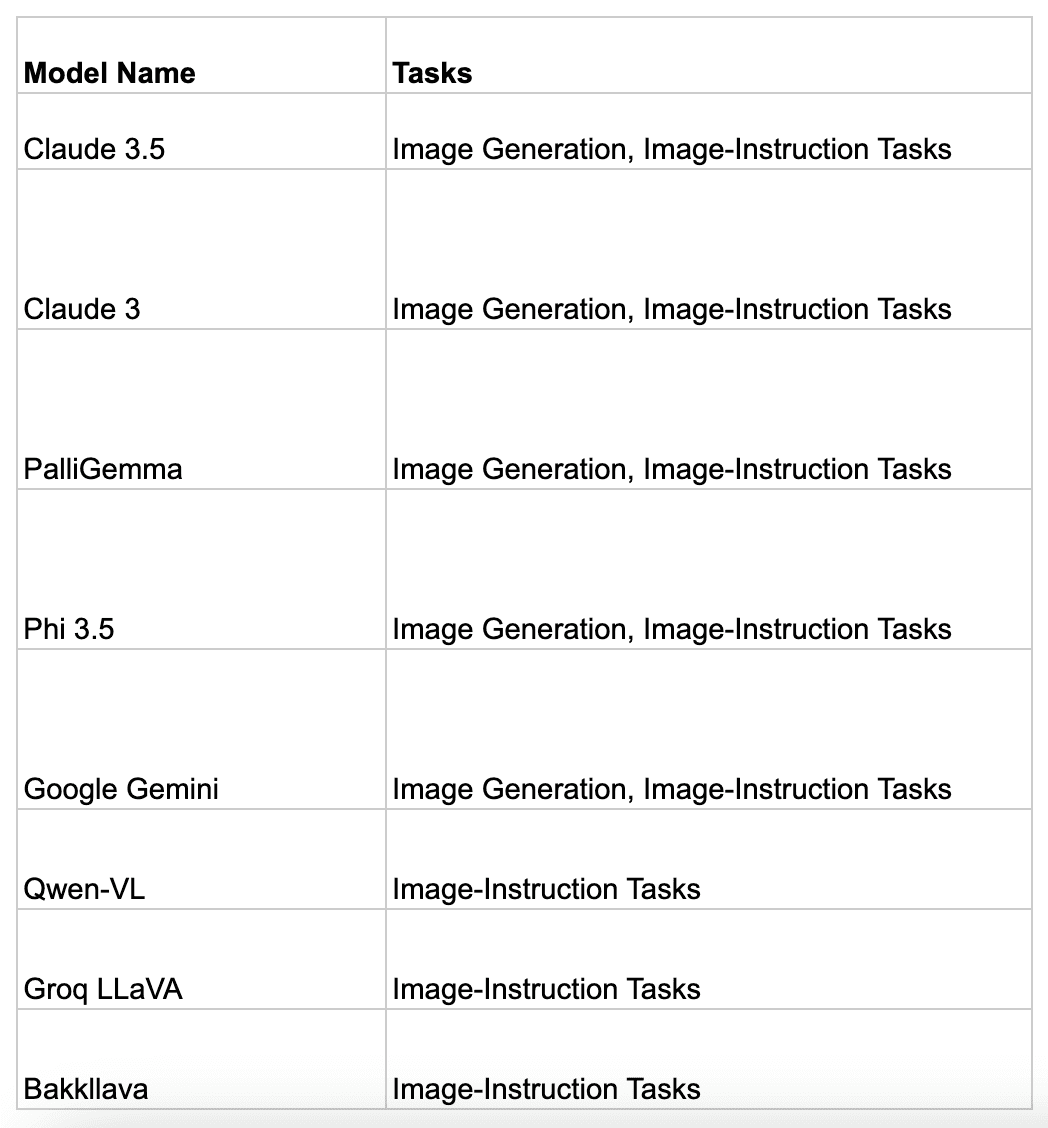
Some Supported VLMs on Tune Studio are:

However, you can also bring VLMs on other private platforms with your API keys for inference. Follow the API reference on “Bringing Your VLM to Tune Studio” to learn more.
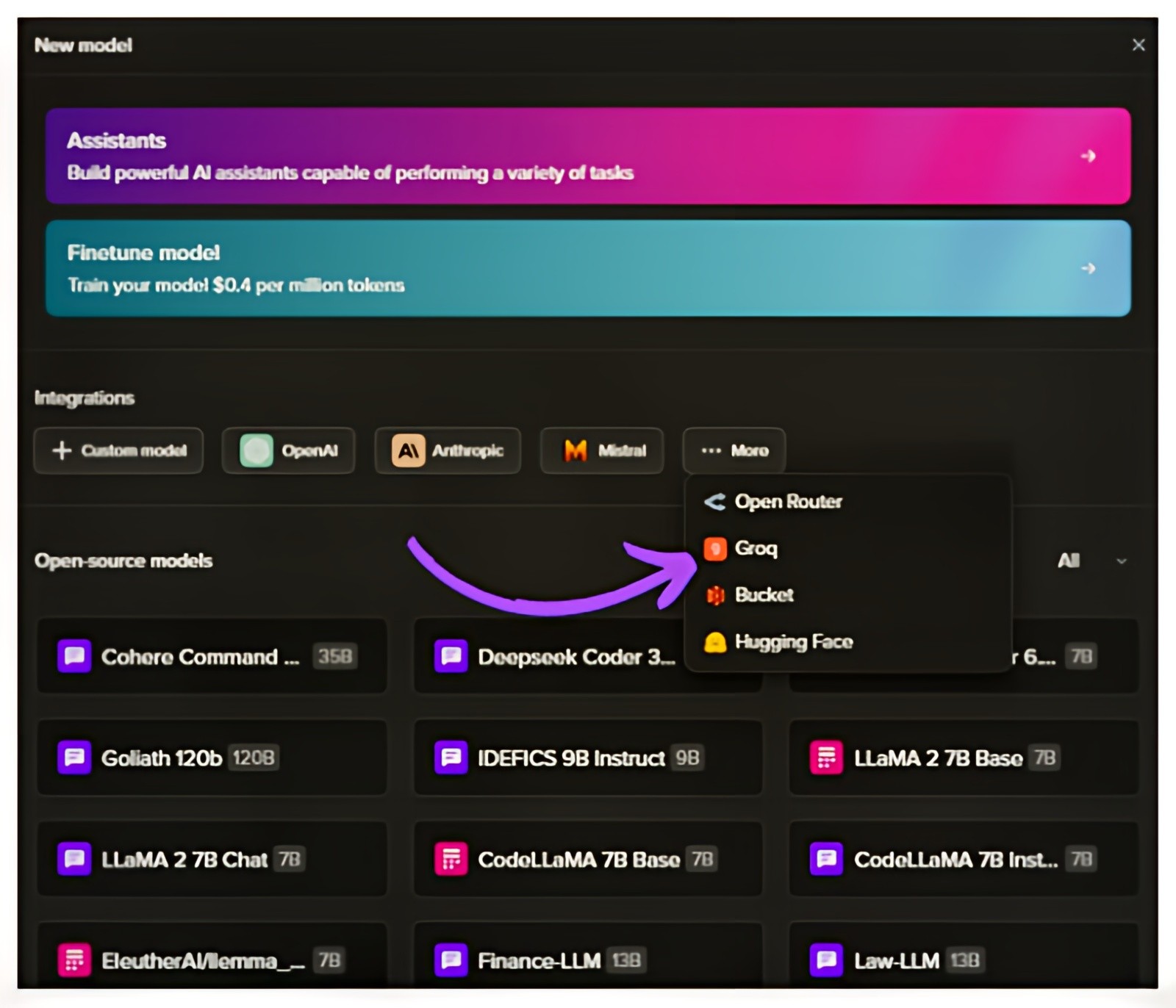
Let us see how one can bring their own VLM to Tune API. We will be bringing llava-v1.5-7b-4096-preview over from Groq:
1. Select New Model from Models on Tune Studio and Select Groq Integration.
2. Add Model ID of Llava v1.5 from Groq Cloud
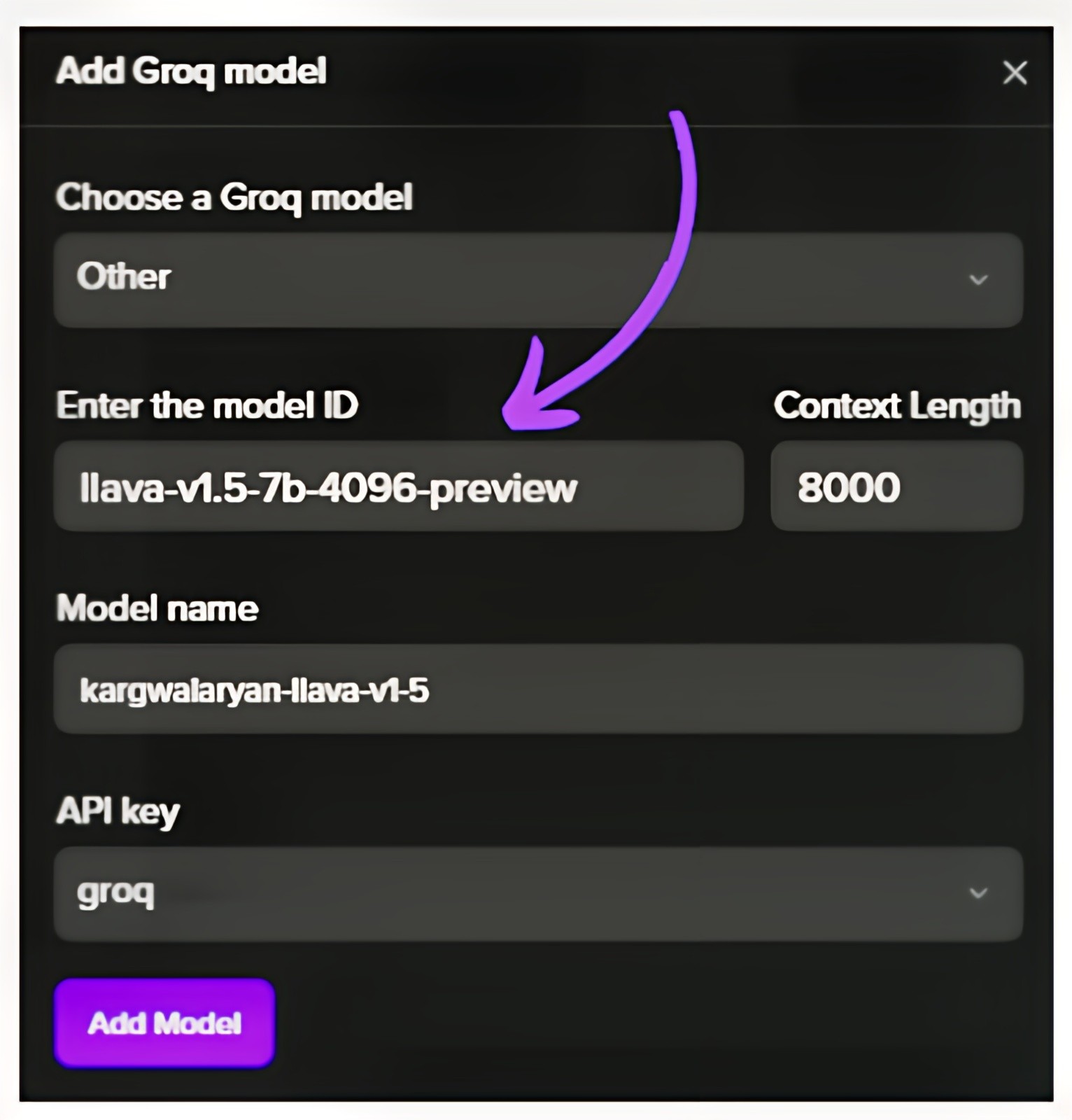
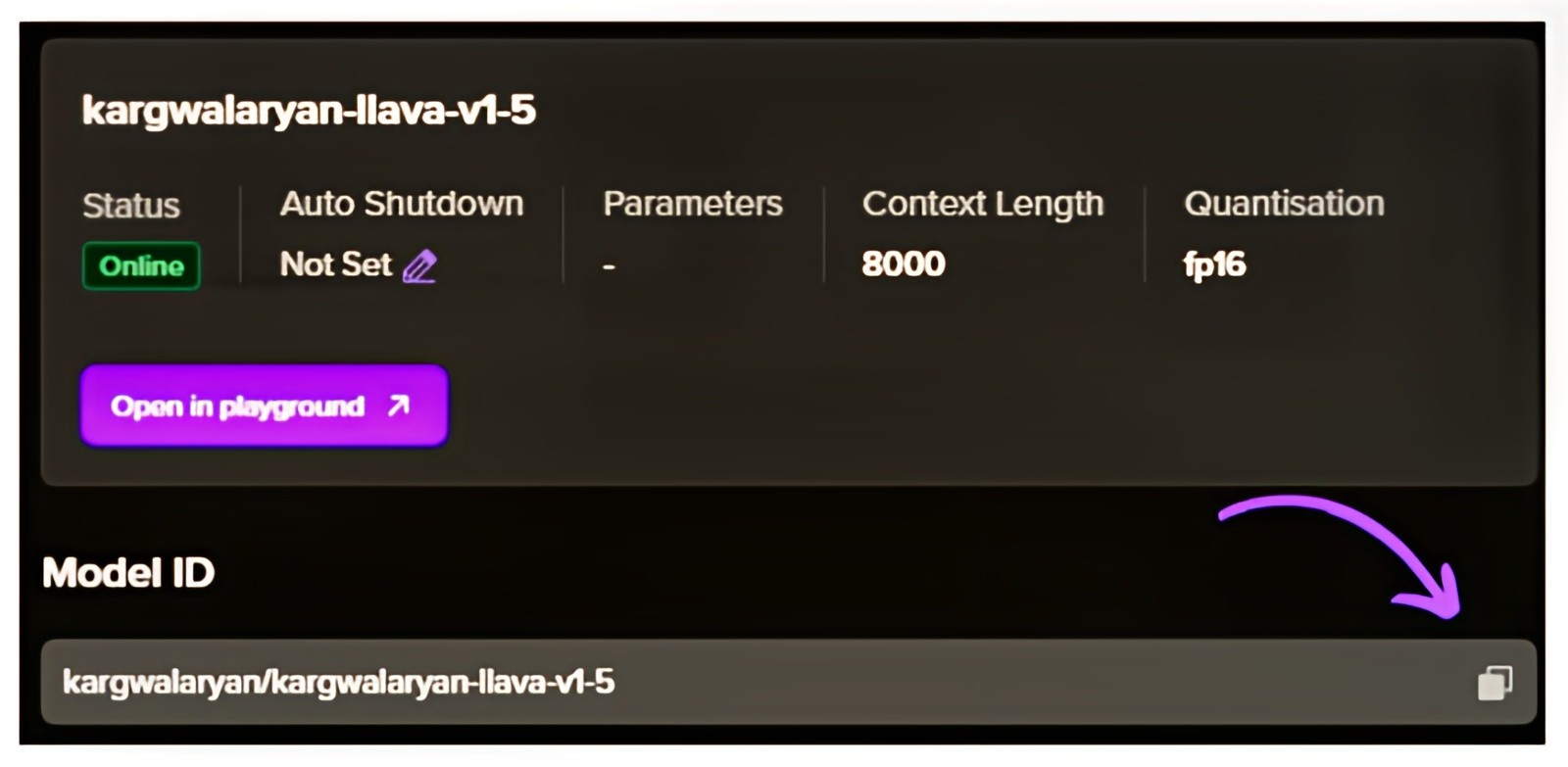
3. Use Newly hosted Llava v1.5 on Tune Studio through the Studio Model ID
Getting Started with Vision QA on Tune Studio
You can interact with vision-enabled models using the following tabs for different methods of accessing the API and the Tune Studio Playground:
Image in URL
To pass an image as a URL you can simply change the type of input to the model to image_link and add the link to the image.
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "https://chat.tune.app/icon-512.png" } } ] } ], "model": "MODEL_ID", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Image in Base 64 Format
To pass an image in base64 format, replace the image section in the API request with the following:
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,{base64_image}" } } ] } ], "model": "MODEL_ID", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Generating Images using Tune Studio
Tune Studio doesn’t support image generation using the API; however, you can generate images directly on Tune Chat and Studio by deploying an image generation model as a Tune Assistant.
Here is how you can achieve that:
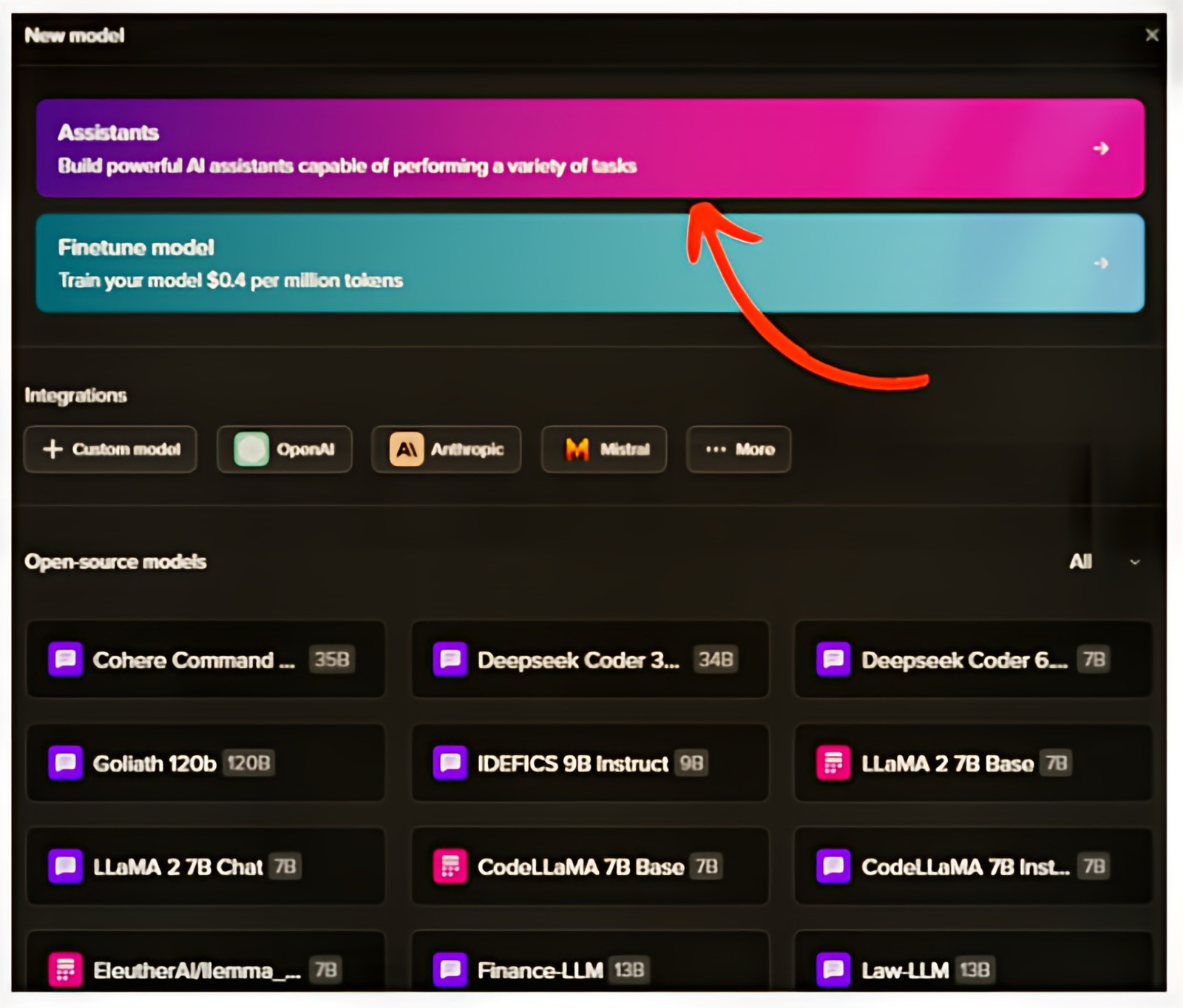
1. Deploy Image Generation Model as an Assistant on Tune Studio
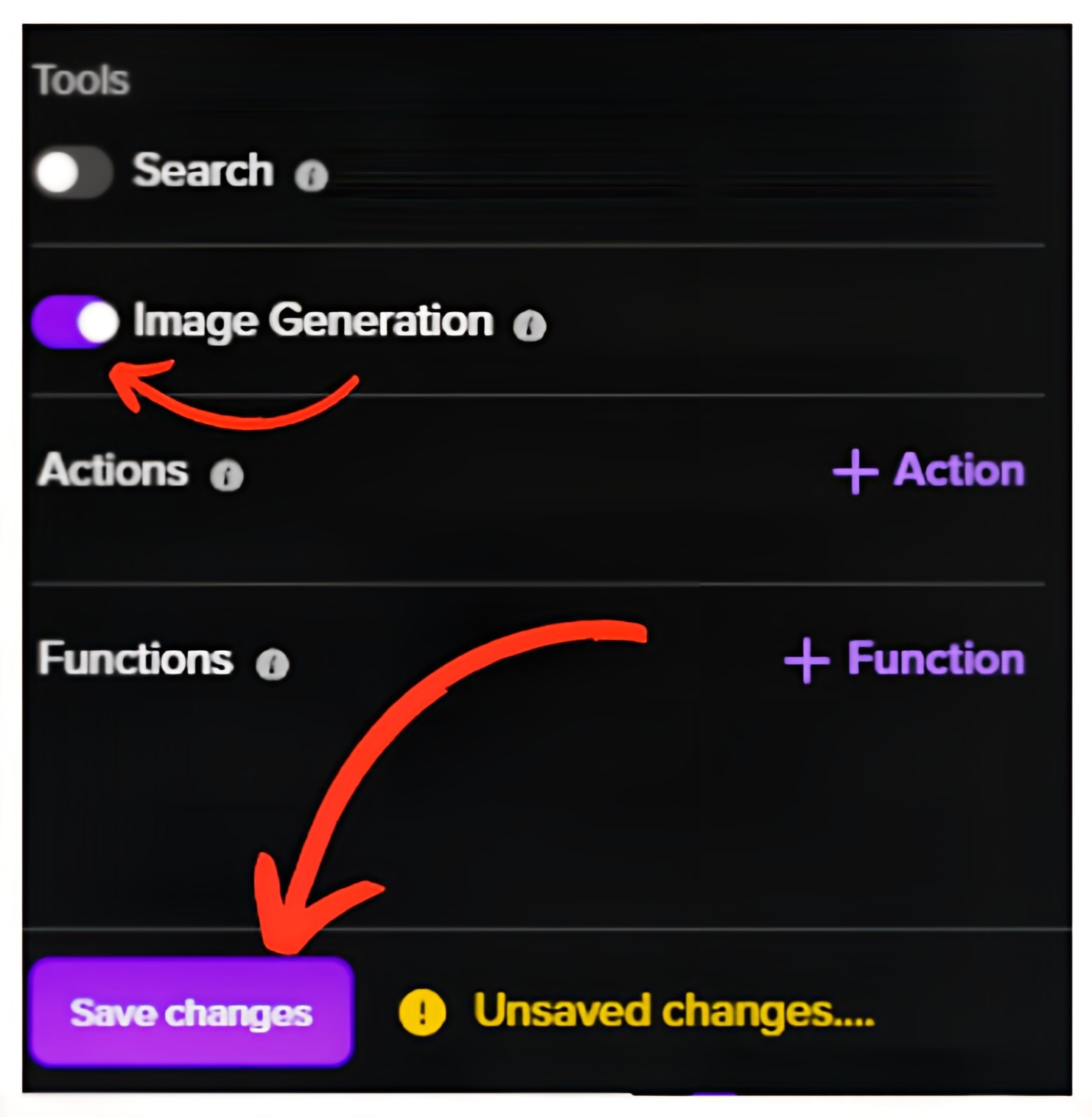
2. Turn on Image Generation for the Assistant and Save Updates
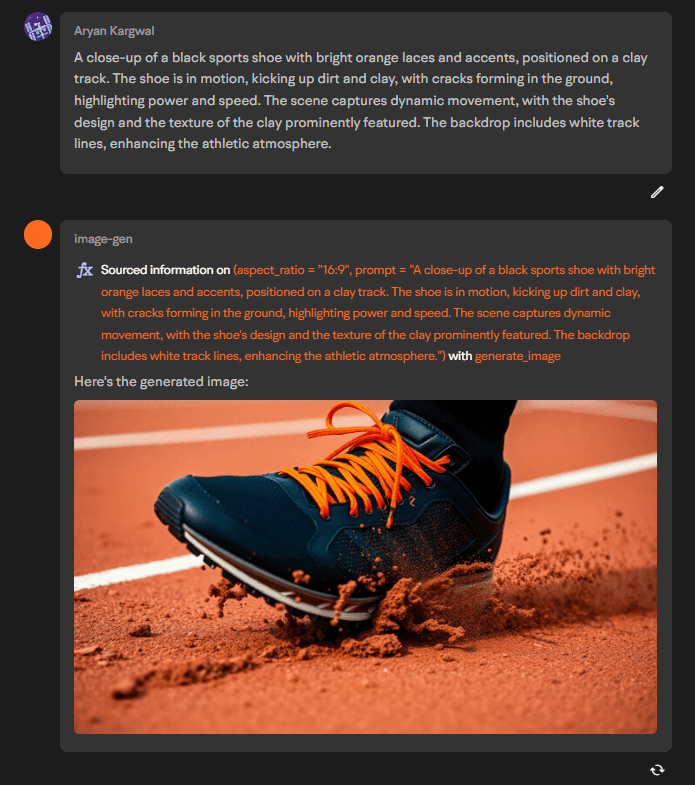
3. Use Playground or Tune Chat for Image Generation
Conclusion
We saw how Vision Language Models are shaping the current generative AI space by being the leading metric most multi-modal LLM giants are trying to perfect. We also saw how users can start interacting with such Vision Language Models on the fly using minuscule code and understanding of the broader technical jargon of these models.
Please let us know what features you would like to see next on our platform by reaching out to us on our socials.
Further Reading
Are you tired of conversing with your model through text and spending countless hours trying to make it understand the weird circuit diagram you are trying to calculate the capacitance for? Would your RAG pipeline tag images for relevant pulls and retrieval? Vision Language Models might just be the touch of Multi-Modal magic you need.
With many Vision Language Models ranging from closed-source to open-source, be it GPT, Claude or Gemini, Tune API lets you easily integrate these models into your pipeline using simple curl commands. In this blog, we shall check out what vision language models are and how you can use them for various applications easily.
What are Vision Language Models?
Vision Language models are a class of GenAI models that act as a step towards achieving multi-modal prowess in such systems by allowing them to interact with images. These models can also harness diffusion techniques to generate images according to their understanding of prompts. Unlike traditional CNN architectures or initial vision transformers, such models let a context-rich large language model seamlessly communicate with images by mapping relevant textual embeddings to corresponding image embeddings.
Some exceptional tasks where these models shine the most are Visual Question Answering, Image Captioning, Multi-Modal Search, and Content Moderation, with visual QA serving as a significant benchmark for their performance and usability. Unlike traditional CNN-based computer vision techniques, Transformer-based models lack a dense understanding of the relationship between different pixels but instead excel in looking at the entire picture at once through patches and making a prediction that sufficiently answers the textual query.
VLM Integrations using Tune API
As the industry has evolved, so have we; Tune Studio and Tune Chat have been actively helping researchers and professionals access these models. Including an array of closed-source and open-source VLMs, users can also go beyond a simple bot chat and integrate these VLMs into their applications through API calls.
Some Supported VLMs on Tune Studio are:
However, you can also bring VLMs on other private platforms with your API keys for inference. Follow the API reference on “Bringing Your VLM to Tune Studio” to learn more.
Let us see how one can bring their own VLM to Tune API. We will be bringing llava-v1.5-7b-4096-preview over from Groq:
1. Select New Model from Models on Tune Studio and Select Groq Integration.
2. Add Model ID of Llava v1.5 from Groq Cloud
3. Use Newly hosted Llava v1.5 on Tune Studio through the Studio Model ID
Getting Started with Vision QA on Tune Studio
You can interact with vision-enabled models using the following tabs for different methods of accessing the API and the Tune Studio Playground:
Image in URL
To pass an image as a URL you can simply change the type of input to the model to image_link and add the link to the image.
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "https://chat.tune.app/icon-512.png" } } ] } ], "model": "MODEL_ID", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Image in Base 64 Format
To pass an image in base64 format, replace the image section in the API request with the following:
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,{base64_image}" } } ] } ], "model": "MODEL_ID", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Generating Images using Tune Studio
Tune Studio doesn’t support image generation using the API; however, you can generate images directly on Tune Chat and Studio by deploying an image generation model as a Tune Assistant.
Here is how you can achieve that:
1. Deploy Image Generation Model as an Assistant on Tune Studio
2. Turn on Image Generation for the Assistant and Save Updates
3. Use Playground or Tune Chat for Image Generation
Conclusion
We saw how Vision Language Models are shaping the current generative AI space by being the leading metric most multi-modal LLM giants are trying to perfect. We also saw how users can start interacting with such Vision Language Models on the fly using minuscule code and understanding of the broader technical jargon of these models.
Please let us know what features you would like to see next on our platform by reaching out to us on our socials.
Further Reading
Are you tired of conversing with your model through text and spending countless hours trying to make it understand the weird circuit diagram you are trying to calculate the capacitance for? Would your RAG pipeline tag images for relevant pulls and retrieval? Vision Language Models might just be the touch of Multi-Modal magic you need.
With many Vision Language Models ranging from closed-source to open-source, be it GPT, Claude or Gemini, Tune API lets you easily integrate these models into your pipeline using simple curl commands. In this blog, we shall check out what vision language models are and how you can use them for various applications easily.
What are Vision Language Models?
Vision Language models are a class of GenAI models that act as a step towards achieving multi-modal prowess in such systems by allowing them to interact with images. These models can also harness diffusion techniques to generate images according to their understanding of prompts. Unlike traditional CNN architectures or initial vision transformers, such models let a context-rich large language model seamlessly communicate with images by mapping relevant textual embeddings to corresponding image embeddings.
Some exceptional tasks where these models shine the most are Visual Question Answering, Image Captioning, Multi-Modal Search, and Content Moderation, with visual QA serving as a significant benchmark for their performance and usability. Unlike traditional CNN-based computer vision techniques, Transformer-based models lack a dense understanding of the relationship between different pixels but instead excel in looking at the entire picture at once through patches and making a prediction that sufficiently answers the textual query.
VLM Integrations using Tune API
As the industry has evolved, so have we; Tune Studio and Tune Chat have been actively helping researchers and professionals access these models. Including an array of closed-source and open-source VLMs, users can also go beyond a simple bot chat and integrate these VLMs into their applications through API calls.
Some Supported VLMs on Tune Studio are:
However, you can also bring VLMs on other private platforms with your API keys for inference. Follow the API reference on “Bringing Your VLM to Tune Studio” to learn more.
Let us see how one can bring their own VLM to Tune API. We will be bringing llava-v1.5-7b-4096-preview over from Groq:
1. Select New Model from Models on Tune Studio and Select Groq Integration.
2. Add Model ID of Llava v1.5 from Groq Cloud
3. Use Newly hosted Llava v1.5 on Tune Studio through the Studio Model ID
Getting Started with Vision QA on Tune Studio
You can interact with vision-enabled models using the following tabs for different methods of accessing the API and the Tune Studio Playground:
Image in URL
To pass an image as a URL you can simply change the type of input to the model to image_link and add the link to the image.
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "https://chat.tune.app/icon-512.png" } } ] } ], "model": "MODEL_ID", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Image in Base 64 Format
To pass an image in base64 format, replace the image section in the API request with the following:
curl -X POST "https://proxy.tune.app/chat/completions" \ -H "Authorization: <access key>" \ -H "Content-Type: application/json" \ -H "X-Org-Id: <organization id>" \ -d '{ "temperature": 0.9, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "What do you see?" }, { "type": "image_url", "image_url": { "url": "data:image/jpeg;base64,{base64_image}" } } ] } ], "model": "MODEL_ID", "stream": false, "frequency_penalty": 0.2, "max_tokens": 200 }'
Generating Images using Tune Studio
Tune Studio doesn’t support image generation using the API; however, you can generate images directly on Tune Chat and Studio by deploying an image generation model as a Tune Assistant.
Here is how you can achieve that:
1. Deploy Image Generation Model as an Assistant on Tune Studio
2. Turn on Image Generation for the Assistant and Save Updates
3. Use Playground or Tune Chat for Image Generation
Conclusion
We saw how Vision Language Models are shaping the current generative AI space by being the leading metric most multi-modal LLM giants are trying to perfect. We also saw how users can start interacting with such Vision Language Models on the fly using minuscule code and understanding of the broader technical jargon of these models.
Please let us know what features you would like to see next on our platform by reaching out to us on our socials.
Further Reading
Written by

Aryan Kargwal
Data Evangelist


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.