LLMs
Theoretical Limits and Scalability of Extra Large Language Models
Jul 23, 2024
5 min read

With the launch of Llama 3 400 B around the corner, most developers are wondering what this model entails. From claims from Meta claiming the model performance is better than GPT 4 on the famous MMLU Benchmark, despite using half the parameters, suggesting the caliber of the model, several questions come to mind.
Questions such as the scale of this model, the theoretical limitations, scalability issues, and most importantly, who is the market? Let us try to look at the same as we try to comprehend the importance of this model.
Understanding the Scale
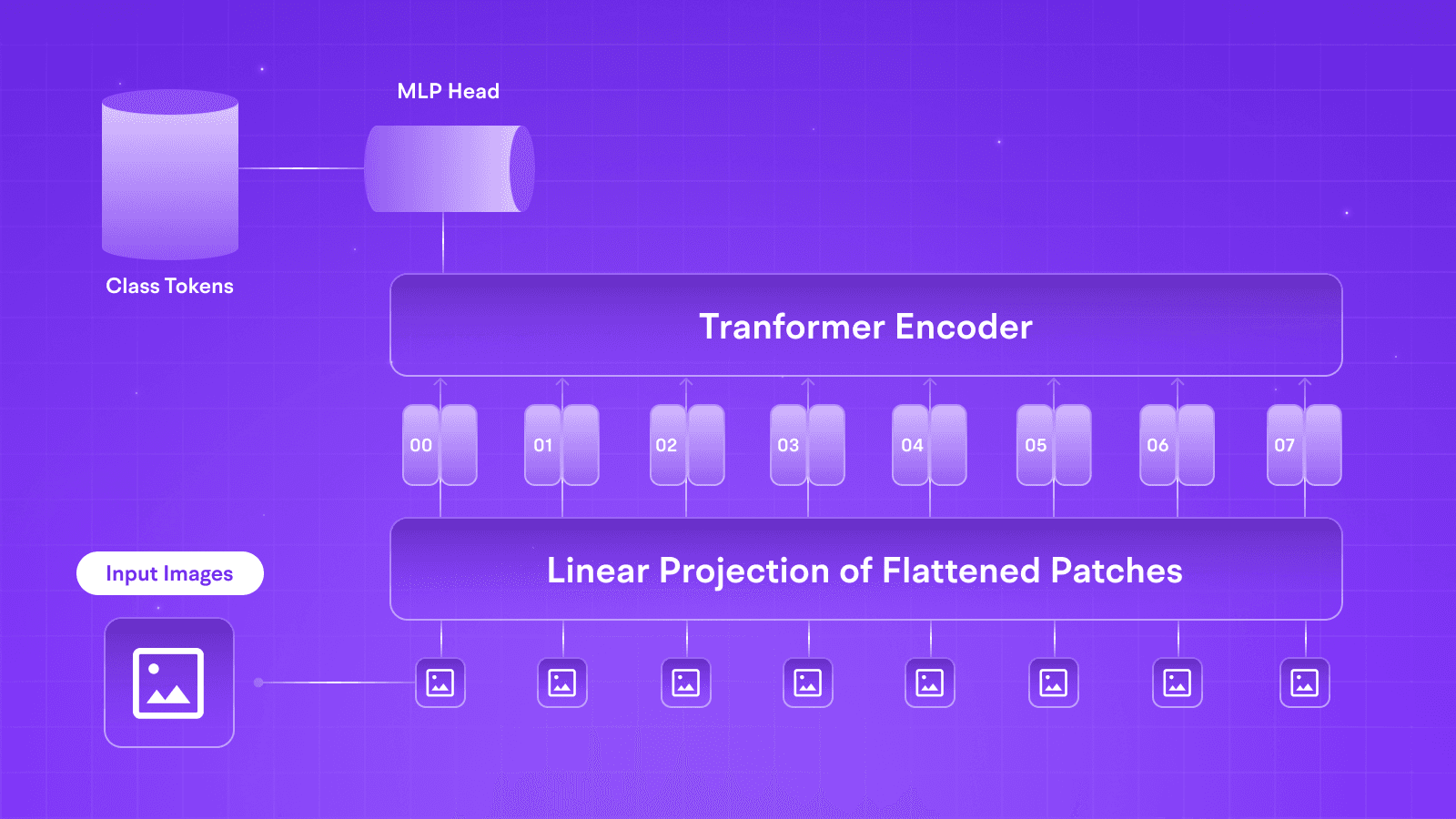
When trying to understand parameters, or more notably the “400B” at the end of this model’s name, parameters can be termed as internal configurations a model learns during training. This simply means that the model in question has 400 Billion such configurations.

Such a model is termed so powerful due to their sheer ability to capture the nuances of a dataset. From just a simple scaler’s ability to retain and learn more data, more parameters mean that the model itself is better at driving connections and recognizing patterns and subtle details in the data.
Theoretical Limits
When talking about the theoretical limits of such a model, a good way is to judge the amount of effort it takes to train such a model. Judging whether training such a model again and again a decision worth the time, effort, and ecological implications, is a question for you!

Before we talk about potential calculations for Llama 3 400 B let me first give you some numbers that had leaked about GPT-4 earlier last year.
Total Parameters: 1.8 Trillion
Training Time: 100 Days
25,000 A 100 Nvidia GPUs
Estimated Cost: $64 Million (Special Deal with Azure)
Adjusted Cost (H100 GPUs in 100 Days): $22 Million
Similar to OpenAI’s top model there are many such “Extra” Large Language Models namely:
Minerva: 540 Billion Parameters
Ernie: 260 Billion Parameters
Falcon: 120 Billion Parameters
Goliath: 120 Billion Parameters
The “limits” in question remain the sheer amount of data required to train such models, along with the electricity and architectures required by such models, the expenses of which sadly can be only afforded by huge organizations. This disparity has unfortunately kept open-source models reach GPT-4 level evaluations, which Llama 3 400 B promises.
Practical Scalability Issues
The expenses however behind such a huge legacy model just get worse as time progresses. Diminishing Returns is one big reason why your favorite model from 2022 is not around anymore. Models due to their expensive training and dynamic retraining costs require constant guardrails, new data training, effective inference infrastructure changes, etc.
An average GPT-4 DGX Node has about 8 x A100 GPUs, which can have either 40GB or 80GB VRAM, which puts the constant VRAM Consumption to run inference for the model is about 320 to 640 GB, which puts a potential Llama 3 400 B Cluster to be around 2 or 4 A 100 GPUs.
Such a model however put into a comparison table with average day-to-day evaluations with models such as GPT 3.5, GPT 4, Llama 3 8B, etc. does not offer a significant performance boost while performing general developer tasks. Then who are the real customers for such a model?
Use Cases
The real customers that can justify the use of such significantly large models are large organizations and institutions that can justify the costs that go into deploying such models. Tech giants, research organizations, and financial institutions are the ones that can use such models for tasks such as products, search engines, virtual assistants, and recommendation systems.
For individual uses however smaller variants of such models that are operating on similar architecture might be the model you are looking for. Finetuned models with medium-size parameters can be better at solving the tasks you are looking for in a much smaller form factor and a justifiable rate to your investors and yourself!
Some popular models that you can use and finetune according to your needs on Tune Studio are:
However for the more curious, don’t worry we will bring Llama 3 400 B as soon as it is available!
Conclusion
In the following blog, we went through the technical and financial difficulties and challenges of “Extra” Large Language Models, trying to shine a light on the potential thought that not every model is made equally, and just a simple glance over the alternatives should help you make a better-informed decision.
Going for well-trained finetuned models may be the difference between millions of dollars spent, which can be done easily thanks to various tools available in the market. Check out some of the following reads to further understand the use of LLMs and gauging performance vs cost!
With the launch of Llama 3 400 B around the corner, most developers are wondering what this model entails. From claims from Meta claiming the model performance is better than GPT 4 on the famous MMLU Benchmark, despite using half the parameters, suggesting the caliber of the model, several questions come to mind.
Questions such as the scale of this model, the theoretical limitations, scalability issues, and most importantly, who is the market? Let us try to look at the same as we try to comprehend the importance of this model.
Understanding the Scale
When trying to understand parameters, or more notably the “400B” at the end of this model’s name, parameters can be termed as internal configurations a model learns during training. This simply means that the model in question has 400 Billion such configurations.
Such a model is termed so powerful due to their sheer ability to capture the nuances of a dataset. From just a simple scaler’s ability to retain and learn more data, more parameters mean that the model itself is better at driving connections and recognizing patterns and subtle details in the data.
Theoretical Limits
When talking about the theoretical limits of such a model, a good way is to judge the amount of effort it takes to train such a model. Judging whether training such a model again and again a decision worth the time, effort, and ecological implications, is a question for you!
Before we talk about potential calculations for Llama 3 400 B let me first give you some numbers that had leaked about GPT-4 earlier last year.
Total Parameters: 1.8 Trillion
Training Time: 100 Days
25,000 A 100 Nvidia GPUs
Estimated Cost: $64 Million (Special Deal with Azure)
Adjusted Cost (H100 GPUs in 100 Days): $22 Million
Similar to OpenAI’s top model there are many such “Extra” Large Language Models namely:
Minerva: 540 Billion Parameters
Ernie: 260 Billion Parameters
Falcon: 120 Billion Parameters
Goliath: 120 Billion Parameters
The “limits” in question remain the sheer amount of data required to train such models, along with the electricity and architectures required by such models, the expenses of which sadly can be only afforded by huge organizations. This disparity has unfortunately kept open-source models reach GPT-4 level evaluations, which Llama 3 400 B promises.
Practical Scalability Issues
The expenses however behind such a huge legacy model just get worse as time progresses. Diminishing Returns is one big reason why your favorite model from 2022 is not around anymore. Models due to their expensive training and dynamic retraining costs require constant guardrails, new data training, effective inference infrastructure changes, etc.
An average GPT-4 DGX Node has about 8 x A100 GPUs, which can have either 40GB or 80GB VRAM, which puts the constant VRAM Consumption to run inference for the model is about 320 to 640 GB, which puts a potential Llama 3 400 B Cluster to be around 2 or 4 A 100 GPUs.
Such a model however put into a comparison table with average day-to-day evaluations with models such as GPT 3.5, GPT 4, Llama 3 8B, etc. does not offer a significant performance boost while performing general developer tasks. Then who are the real customers for such a model?
Use Cases
The real customers that can justify the use of such significantly large models are large organizations and institutions that can justify the costs that go into deploying such models. Tech giants, research organizations, and financial institutions are the ones that can use such models for tasks such as products, search engines, virtual assistants, and recommendation systems.
For individual uses however smaller variants of such models that are operating on similar architecture might be the model you are looking for. Finetuned models with medium-size parameters can be better at solving the tasks you are looking for in a much smaller form factor and a justifiable rate to your investors and yourself!
Some popular models that you can use and finetune according to your needs on Tune Studio are:
However for the more curious, don’t worry we will bring Llama 3 400 B as soon as it is available!
Conclusion
In the following blog, we went through the technical and financial difficulties and challenges of “Extra” Large Language Models, trying to shine a light on the potential thought that not every model is made equally, and just a simple glance over the alternatives should help you make a better-informed decision.
Going for well-trained finetuned models may be the difference between millions of dollars spent, which can be done easily thanks to various tools available in the market. Check out some of the following reads to further understand the use of LLMs and gauging performance vs cost!
With the launch of Llama 3 400 B around the corner, most developers are wondering what this model entails. From claims from Meta claiming the model performance is better than GPT 4 on the famous MMLU Benchmark, despite using half the parameters, suggesting the caliber of the model, several questions come to mind.
Questions such as the scale of this model, the theoretical limitations, scalability issues, and most importantly, who is the market? Let us try to look at the same as we try to comprehend the importance of this model.
Understanding the Scale
When trying to understand parameters, or more notably the “400B” at the end of this model’s name, parameters can be termed as internal configurations a model learns during training. This simply means that the model in question has 400 Billion such configurations.
Such a model is termed so powerful due to their sheer ability to capture the nuances of a dataset. From just a simple scaler’s ability to retain and learn more data, more parameters mean that the model itself is better at driving connections and recognizing patterns and subtle details in the data.
Theoretical Limits
When talking about the theoretical limits of such a model, a good way is to judge the amount of effort it takes to train such a model. Judging whether training such a model again and again a decision worth the time, effort, and ecological implications, is a question for you!
Before we talk about potential calculations for Llama 3 400 B let me first give you some numbers that had leaked about GPT-4 earlier last year.
Total Parameters: 1.8 Trillion
Training Time: 100 Days
25,000 A 100 Nvidia GPUs
Estimated Cost: $64 Million (Special Deal with Azure)
Adjusted Cost (H100 GPUs in 100 Days): $22 Million
Similar to OpenAI’s top model there are many such “Extra” Large Language Models namely:
Minerva: 540 Billion Parameters
Ernie: 260 Billion Parameters
Falcon: 120 Billion Parameters
Goliath: 120 Billion Parameters
The “limits” in question remain the sheer amount of data required to train such models, along with the electricity and architectures required by such models, the expenses of which sadly can be only afforded by huge organizations. This disparity has unfortunately kept open-source models reach GPT-4 level evaluations, which Llama 3 400 B promises.
Practical Scalability Issues
The expenses however behind such a huge legacy model just get worse as time progresses. Diminishing Returns is one big reason why your favorite model from 2022 is not around anymore. Models due to their expensive training and dynamic retraining costs require constant guardrails, new data training, effective inference infrastructure changes, etc.
An average GPT-4 DGX Node has about 8 x A100 GPUs, which can have either 40GB or 80GB VRAM, which puts the constant VRAM Consumption to run inference for the model is about 320 to 640 GB, which puts a potential Llama 3 400 B Cluster to be around 2 or 4 A 100 GPUs.
Such a model however put into a comparison table with average day-to-day evaluations with models such as GPT 3.5, GPT 4, Llama 3 8B, etc. does not offer a significant performance boost while performing general developer tasks. Then who are the real customers for such a model?
Use Cases
The real customers that can justify the use of such significantly large models are large organizations and institutions that can justify the costs that go into deploying such models. Tech giants, research organizations, and financial institutions are the ones that can use such models for tasks such as products, search engines, virtual assistants, and recommendation systems.
For individual uses however smaller variants of such models that are operating on similar architecture might be the model you are looking for. Finetuned models with medium-size parameters can be better at solving the tasks you are looking for in a much smaller form factor and a justifiable rate to your investors and yourself!
Some popular models that you can use and finetune according to your needs on Tune Studio are:
However for the more curious, don’t worry we will bring Llama 3 400 B as soon as it is available!
Conclusion
In the following blog, we went through the technical and financial difficulties and challenges of “Extra” Large Language Models, trying to shine a light on the potential thought that not every model is made equally, and just a simple glance over the alternatives should help you make a better-informed decision.
Going for well-trained finetuned models may be the difference between millions of dollars spent, which can be done easily thanks to various tools available in the market. Check out some of the following reads to further understand the use of LLMs and gauging performance vs cost!
Written by

Aryan Kargwal
Data Evangelist
Edited by

Abhishek Mishra
DevRel Engineer


Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.

Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.
Enterprise GenAI Stack.
LLMs on your cloud & data.
© 2025 NimbleBox, Inc.